Cloud File Server Consolidation Overview
Maybe your business has outgrown its file servers and you’re thinking of replacing them. Or your servers are located throughout the world, so you’re considering shutting them down and moving to the cloud. It might be that you’re starting a new business and wondering if an in-house server is adequate or if you should adopt cloud technology from the start.
Regardless of why you’re debating a physical file server versus a cloud-based file server, it’s a tough decision that will impact your business on a daily basis. We know there’s a lot to think about, and we’re here to show why you should consolidate your physical file servers and move your data to the cloud.
We’ll discuss the state of the file server market and talk about the benefits of cloud file sharing. What we’re going to talk about is some of the challenges and some of the newest technologies to step up to the challenges of unstructured data not only sitting in one place but scattered around the world.
Managing Unstructured Data
The image below is how Gartner looks at unstructured data in the enterprise. The biggest footprint of data that you have as an enterprise or a commercial user is your unstructured data. It’s your files.

That one is where you buy a large single platform that might be a petabyte or even larger to house all of that file data, but what creeps up on us is the data that doesn’t leave in the data, that which isn’t right under your nose and surrounded by best practices. And those who distribute file servers that live around the world, on average an enterprise with 50 locations, be they branch offices, distribution centers, manufacturing facilities, oil rigs, etc, they’ve got 50 or 100 locations, they’re going to have at least 50 or 100 data centers.
The analyst community (Gartner, Forrester and 451) tell us that almost 80% of the unstructured data you’re dealing with actually sits outside of your well protected data center. This presents challenges for an enterprise because it’s outside of your control.
It’s been difficult to leverage the cloud for unstructured data. Customers by and large are being fairly successful moving workloads and applications to the cloud, along with the storage those applications use. However, when you’re talking about user data and your users are all around the world, you’re dealing with distance, latency, network unavailability in general and multiple hubs through routing.
Which has led to some significant challenges, such as having the situation where you’ve data islands popping up everywhere. You have massive amounts of corporate data that’s not subject to the same kind of data management security that you would have in an enterprise datacenter. Including backup, recovery, audit, compliance, secure networks and even physical access.
And that is what has led to a really “bleeding from the neck problem.” That being, how am I going to get this huge amount of data around the world under our control?
Unstructured Data Challenges
These are some of the issues that you find: Security problems, lost files. Users calling in and saying, “Oops, I made a mistake. Can you restore this for me?” And the answer quite often is, “No. You people in that location are supposed to be backing up your own file server.”
Bandwidth issues are significant as people are trying to have everyone in the world work from a single version of the truth and they’re trying to all look at the same data. But how do you do that when it’s file data?
You have a location in London trying to ship big files to New York. NY then makes some changes and ships the files to India. Yet people are in different time zones. How do you make sure they’re all working off of the same version of information? That has led to the kind of problems driving people to the cloud. Large enterprises are trying to get to the cloud not only with their applications, but with their data.
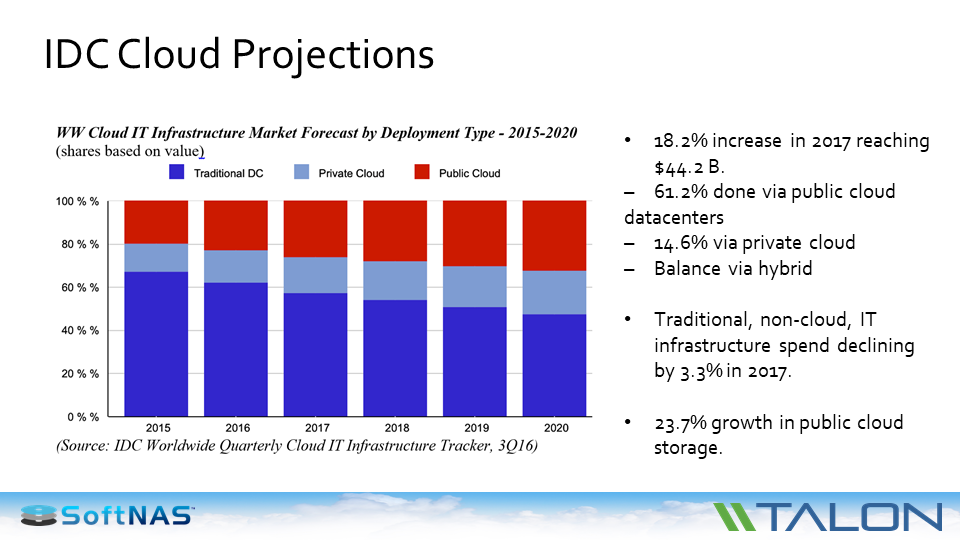
If you look at what Gartner and IDC say about the move to the cloud, you see that larger enterprises have a cloud-first strategy. We’re seeing SMBs (small and medium businesses) and SMEs (small and medium enterprises) also have a cloud-first strategy. They’re embracing the cloud and moving significant amounts of their workloads to the cloud.
More companies are going to install a cloud IT infrastructure at the expense of private clouds. We see customers all the time that are saying, “I have 300,000 sq ft. data center. My objective is to have a 100,000 sq ft. data center within the next few months.”
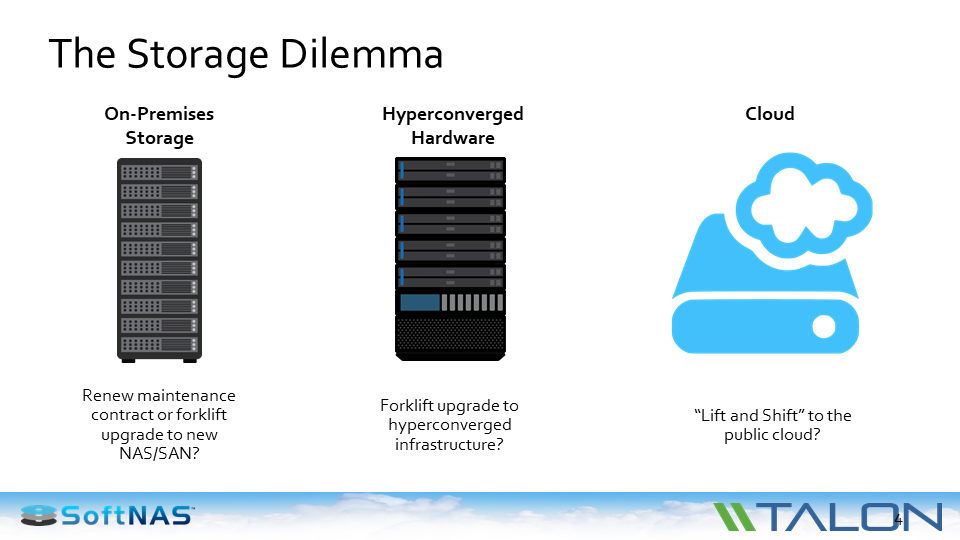
NAS/SAN vs. Hyperconverged vs. The Cloud
And so many customers are now saying, “What am I going to do next? My maintenance renewal is coming up. My capacity is reaching its limit because unstructured data is growing in excess of 30% annually in the enterprise. So what is the next thing am I going to do?”
Am I going to add more on-premise storage to my files? Am I going to take all of my branch offices that are currently 4 terabytes and double them to 8 terabytes?
You probably have seen the emergence of hyperconverged hardware — single instance infrastructure platforms that do applications, networking and storage. It’s a newer, different way of having an on-premise infrastructure. With a hyperconverged infrastructure, you still have some forklift upgrade work both in terms of the hardware platform and in terms of the data.
Customers that are moving off of traditional NAS and SAN systems onto hyperconverged have to bring in the new hardware, migrate all the data, get rid of the old hardware, so it’s still lift and shift from a datacenter as well as a footprint.
Because of that, a lot of SoftNAS customers are asking, “Is it possible to do a lift and shift to the cloud? I don’t want to get the infrastructure out of my data center and out of my branch offices. I don’t want to be in the file server business. I want to be in the banking, or the retail, or the transportation business.”
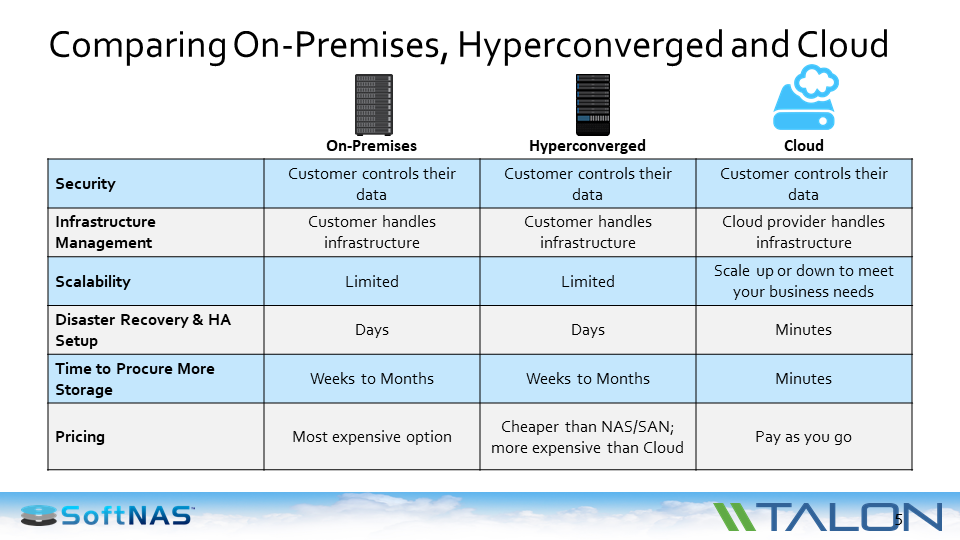
I want to let the cloud providers — Azure, AWS, or Google — to use their physical resources, but it’s my data and I want everybody to have access to it. That’s opened the world to a lift and shift into a cloud-based infrastructure. That means you and your peers are going through a pros and cons discussion. If you look at on-premises versus hyperconverged versus the cloud, the good news is all of them have an secure infrastructure available. That could be from the level of physical access, authentication and encryption – either in-transit or at-rest or in-use, all the way down to rights management.
What you’ll find is that all the layers of security apply across the board. In that area, cloud has become stronger in the last 24 months. In terms of infrastructure management — which is getting to be a really key budget line item for most IT enterprises — for on-premise and hyperconverged, you’re managing that. You’re spending time and effort on physical space, power, cooling, upgrade planning, capacity planning, uptime and availability, disaster recovery, audit and compliance.
The good news with the cloud is you get to off load that to someone else. Probably the biggest benefit that we see is in terms of scalability. It’s in terms of the businesses that say, “I have a pretty good handle on the growth rates of my structured data but my unstructured data is a real unpredictable beast. It can change overnight. We may acquire another company and find out we have to double the size of our unstructured data share. How do I do that?” Scalability is a complicated task if you’re running an on premise infrastructure.
With the cloud, someone else is doing it — either at AWS, Azure, Google, etc. From a disaster recovery perspective, you pretty much get to ride on the backs of established infrastructure. The big cloud providers have great amounts of staff and equipment to ensure that failover, availability, pointing to a second copy, roll-back etc, has already been implemented and tested.
Adding more storage becomes easy too. From a financial perspective, the way you pay for an on-premise environment, is you buy your infrastructure and you use it. It’s the same thing with hyperconverged. Although, they have lower price points than traditional legacy NAS and SAN. But the fact is only the cloud gives you the ability to say “I’m going to pay for exactly that I need. I’m not buying 2 Terabytes because I currently need 1.2 Terabytes and I’m growing 30% per annum.” If you’re using 1.2143 terabytes, that’s what you pay for in the cloud.
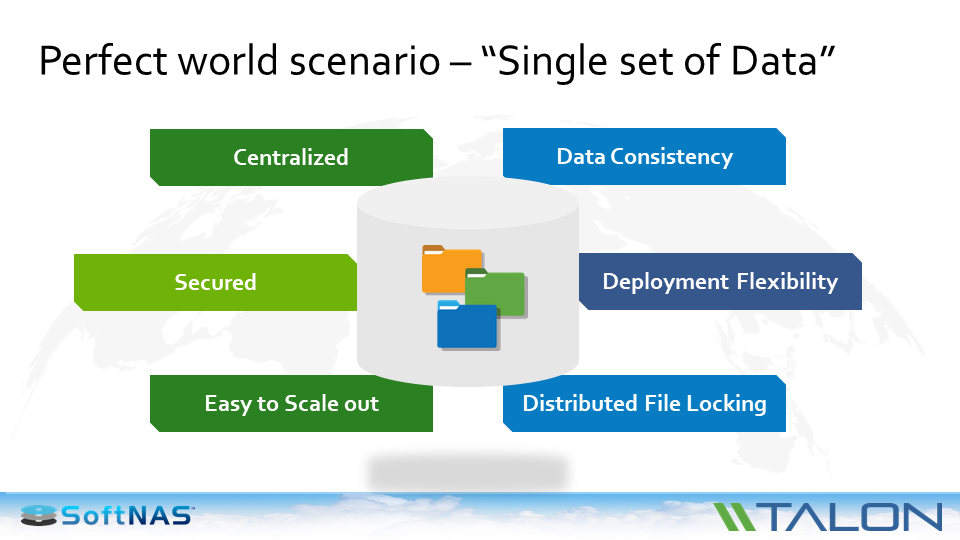
A Single Set of Data
But just as important, they have found out that there is a business use-case. There is the ability to do things from a centralized consolidated cloud viewpoint which you simply cannot do from the traditional distributed storage infrastructure.
If you think about what customers are asking for now, more and more enterprises are saying “I want centralized data.” That’s one of the reasons they’re moving to the cloud. They want security. They want to make sure that it’s using best practices in terms of authentication, encryption, and token management. And whatever they use has to be able to scale up for their business.
But how about from a use case perspective? You need to make sure you have data consistency. Meaning, if I have people on my team in California, New York and London, I need to make sure they’re not stepping on each other’s work as they collaborate on projects.
You need to make sure you have flexibility. If you’re getting rid of old infrastructure in 20 or 30 branch offices, then you need to get rid of them easily and quickly spin up the ability for them to access centralized data within minutes. Not within hours and weeks of waiting for new hardware to come in.
Going back to data consistency, if I’m going to have one copy of the truth that everyone is using, I need to make sure that I have that distributed files working. Because face it, that what file servers do. That is the foundation of file servers since they were invented in the market. Those are the type of benefits that are being brought to bear by people that move their file servers into the cloud. They cut costs and increase flexibility.
Cloud File Server Reference Architecture
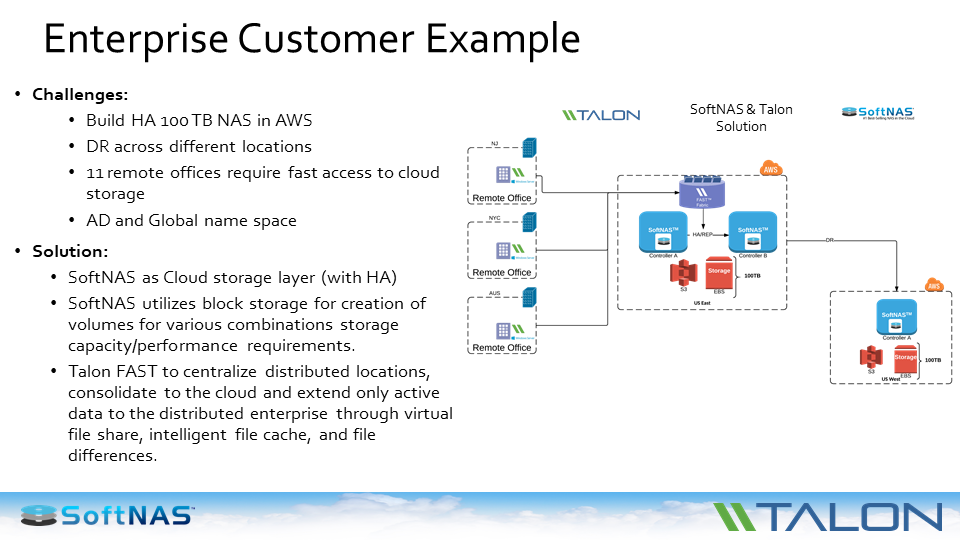
Here’s an example. In the image below, a SoftNAS customer needed to build a highly available 100 TB Cloud NAS on AWS. The NAS needs to be accessed in the cloud via a CIFS protocol and they need to have data elsewhere. Not the primary location, but they need to have across the region and different continents.
They needed to have to have access from the remote office. Also, they need Active Directory and giving them a need to have them for the help build a new space with the district file locking as well.
The solution provided along with Talon FAST, deployed two instances in UFCs. In this case in two separate zones — control A deployed in one zone and control B deployed in the second zone. We leveraged S3 and EBS for different type of applications for their SLA.
We set up replication between two nodes so the data is available in two different places and is within the zone. We deployed HA on top of it to give that availability with minimal down time. So we give you that flexibility to migrate data or flip to another node without management intervention.
Next Steps
You can also try SoftNAS Cloud NAS free for 30 days to start consolidating your file servers in the cloud: