The Three Strategies to Increase Performance for Your Applications in AWS
“3 strategies to increase performance for your applications in AWS.” You can download the full slide deck on Slideshare.
AWS Application Performance
Many customers have tried building these applications in their data centers and they are designed for extremely fast storage. As they are migrating their line of business applications to the cloud, a lot of their applications worked and didn’t have a constraint on access to the storage.
But a few of those applications would not run or will not run in the cloud with acceptable performance because of the demand, the type of application that it is, and the connections or the throughput or the latency to get the data off of the storage and back into the application or put it back on to the storage. They weren’t getting the performance that they needed, so they tried using AWS EFS. They tried using AWS FSx. They tried using maybe some open-source NAS and they weren’t getting the performance until they discovered SoftNAS.
SoftNAS push to make the AWS application run with great performance
SoftNAS then had the appropriate levers to pull, and buttons to push to make the application run with great performance, and we’re going to do a deep dive into why we have some statistics on some performance benchmarking we did that prove some of these things.
Companies trust Buurst for data performance, data migration, data cost control, high availability, control, and security. When we think about this scenario of performance, there are two different camps, let’s say. There are managed storage services, and they are great because someone else is managing your storage layer for you. Then there’s a cloud NAS (network attached storage) like SoftNAS, so this sits in between your cloud clients and your on-premises clients and your storage.
Managed Storage Service

For managed storage services like AWS EFS or AWS FSx
First of all, they serve many different companies or customers and they throw security in so company A can get to company B. The other end of that is they limit the amount of throughput that each company has to access storage so one of them does not become a noisy neighbor.
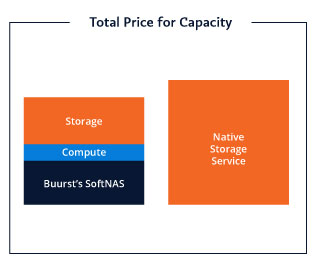
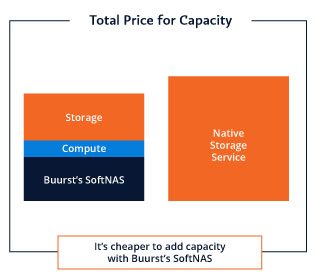
Then we have like SSD and HD in cold storage on the backend there that we have access to, so we can always just go to a faster disk or things like that to get better performance, but that comes with a price. To really think about increasing the performance of a managed storage service, we have two main levers we can pull and push. It’s we can purchase more storage or we can purchase more throughput.
Increase AWS Performance by Increasing Storage

This chart is based on the AWS EFS and FSx websites. What it’s telling me is the more gigs I have purchased; the more throughput I have.
For instance, the very top one on AWS EFS, if I purchase 10 gigs, I get 0.5 per second and it’s going to cost me $3 a month. If my solution requires that I have 100 megs of throughput, I need to purchase two terabytes of storage. That will cost me $614 a month, and that’s fine.
To get more performance, I can increase the amount of storage. I can also increase my throughput by purchasing provisioned throughput.
In this instance here, in this case, I needed that 100 megs of throughput, and I can purchase that. I’m basically buying two terabytes of storage. Even if I only have one terabyte of storage but I need 100 megs of throughput, I’m basically still purchasing two terabytes of storage but I’m provisioned with 100 megs.
The same thing with 350, I’m eight terabytes. With 600 megs, I’m basically purchasing 16 terabytes of storage for the throughput performance that I require. Now that’s great. Like I said earlier, in a lot of applications, that runs very well and it’s fine. But for those applications that it doesn’t quite work for, they turn to SoftNAS AWS. They turn to a cloud NAS.
SoftNAS for better AWS Application Performance
AWS application performance

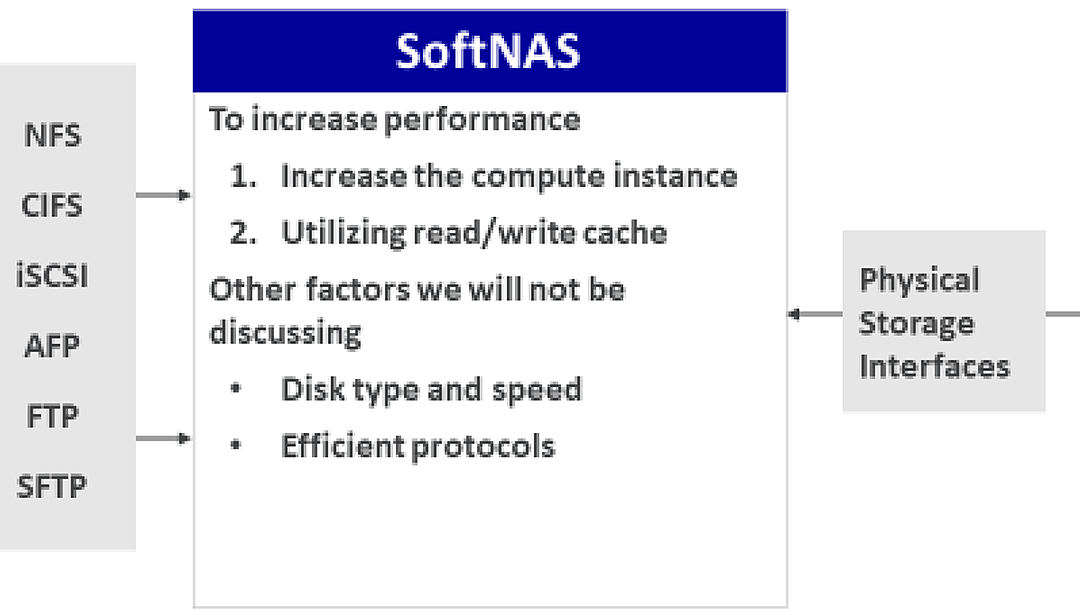
With SoftNAS, I can use an efficient protocol. If it’s a SQL Server solution, I can use iSCSI. If it’s Linux, I can use NFS, windows, I can use CIFS, and it could all connect to the same amount of storage I can control and manage off my NAS.
I can use different disks speeds or more disks. I can use more smaller disks than fewer larger disks in my RAID array. I can do things like that. For this conversation, we’re going to talk about the cool ways to increase performance and manage costs.
I can increase the compute instance, and I can increase the read/write cache of my SoftNAS. Let’s dive into that. In AWS, I have compute instances for my NAS. In this case, I have an m3.xlarge. I have 4VCU and 15 megs of RAM, and I get 100-megabyte throughput.
That’s the throughput from my NAS to my clients because all the storage is directly connected to my NAS. I have a c5.9xlarge, 36 VCPUs, 17 megs of RAM. I get 1,200 megs of throughput. Remember that’s from my NAS to my clients.
For my NAS to my storage, that’s directly connected to my NAS. In AWS, I can connect about a petabyte of storage. I can also utilize caching. We know how important caching is. On my NAS, I have an L1 cache which is RAM, and I have an L2 cache which is a dedicated disk to a specific storage pool.
With SoftNAS, by default, I use half of the available RAM. If I have 32 megs of RAM, I can get 16 meg of that by default, available for L1 cache.
For L2 cache, I can use NVMe or SSD. For instance, let’s say I have a SQL Server solution that I’m providing data to and all my storages are on an array. That’s great. I can have NVMe dedicated to that pool servicing that SQL Server and my solution is just humming.
Then I could have another pool, let’s say it’s all my web servers data, that are in an array. I can have all of that with a bigger SSD drive for the cache. I can tune my solution in my NAS controller.
We ran a performance benchmark on AWS EFS against SoftNAS on AWS. Because so many customers were coming to us and saying, “We came to you because you gave us the performance that we needed,” we really wanted to dive down and try to figure out why or how.
To just summarize, throughput is a measurement of how fast your storage can read and write the data. In IOPS, the higher the IOPS; the faster you have access to the data on that disk. Latency is a measurement of the time it takes for a component or a subsystem to process the data request or transaction.
How do we do it?
Well, we have a Linux fio Server with four Linux fio clients through NFS connecting either to SoftNAS with no L2 cache or AWS EFS, with SSD storage on both. We had a basic, medium, and high.
Basic was 100 Megabits per second. Medium was 350 megs per second. High was 600 megs per second. We gave them different amounts of storage to give more throughput to the storage on AWS EFS.
For storage throughput, what we learned was the more RAM, CPU, and network we gave to the NAS the better numbers we got. And we were able to provide continuously sustained throughput and predictable performance because we weren’t throttling any other customers.
Throughput (MiB\s) – Higher is Better

What we found was pretty remarkable. On our basic, we are almost twice the performance. When we got to our higher-end, we are 23% at all times — 23 times the performance in the higher end for read/write sequential and read/write random of a 70/30 combo there.
On IOPS, again what we learned was the more CPU, RAM, and network speed, we got better IOPS. We know we could have used a faster disk such as NVMe, and that’s how we got a million IOPS on AWS. We could have added more disks to an array to aggregate and increase the disk IOPS. We could have done that also, but we didn’t.
IOPs – Higher is Better

What we found is, again, we were almost two times the performance on IOPS on our basic. I think we are around 18 times on the medium and 23 times the performance on the higher end — just huge numbers that we are really proud of.
For the latency, how can I get that data or the time it takes to get that data off and on that disk. What we found is no surprise. If I increase the CPU, the RAM, and network speed, I decrease latency. I could have decreased latency by using NVMe, but that adds a substantial cost.
Latency – Lower is Better

I could have decreased latency by using smaller and more disks than larger disks. Again, these results were kind of the same. We were two times lower. We’re about 18 times lower in our midrange there. In our high end, we’re about 23 times lower.
Now, all of that data, we’ve published. It’s on our blog in burst.com and it’s an I-chart. If you want to dive into this data, we’d be more than happy to talk with you on how we achieve these numbers, try to replicate these numbers, or give you a demo on how we think we can increase the performance of your specific application.
Let’s talk about specific applications where there’s throughput, IOPS, or latency.
For throughput, if you have many client connections like a web server array or even just cloud virtual desktops or actual desktops on-premises, you have lots of clients accessing the data. You need more throughput.
Maybe they are accessing video files, office files, AutoCAD files, or web server content — more throughput. Like one of our great partners, Petronas, had many clients out there that needed access to the content. SoftNAS was able to handle the amount of clients accessing the data.
When we’re talking about IOPS, we’re talking about small block size transactions like a database server or an email server who need to access the data and put data in very small chunks. We have a great partner, Halliburton, for instance. Their application for the oil and gas industry — their landmark application — they take the seismic data, just massive amounts of data.
It has to pull it off of the disk and then render it to show it visually to the plate-tectonic engineers. They were able to get their application, import it, and move to the cloud in record speed with SoftNAS and then have it run at a great performance level with SoftNAS. Absolutely fantastic.
On latency, think about applications like banking, stock exchange, finance who need fast access in and out of that data as fast as they can, or streaming. Netflix is a great partner of ours. To provide the solution for great cloud partners like AWS accessing the cloud storage, providing NetApp to the application.
How do I increase performance with AWS applications?
We’ve got to understand what the bottlenecks are. How does the AWS application perform? Does it need throughput? Does it need IOPS? Does it need low latency?
How to Increase Performance for Your AWS Application
- Understand your solution and where the bottlenecks are
- Throughput
- IOPs
- Latency
- Then understand if managed storage will work for you
- Reach out to SoftNAS to better understand your AWS performance options to develop a solution to meet the specification of your workload

When we understand that, then we can understand if managed storage can work for you. That’s great. If it’s not, come talk to us. Meet a cloud storage performance professional and just talk about some ideas, what you’re seeing out there, why won’t it work. We’ve helped so many customers.
We have helped tons of customers get their applications running on AWS. We were the first NAS up there. We started that whole industry of NAS in the cloud. We have lots of information on performance blogs. We have an e-book.
We have a dedicated performance web page at burst.com/performance. We’d love to show you our product. To get a demo, talk to a performance professional. At Buurst, we are a data performance company. That’s all we want to do, live and breathe and think and provide you the fastest access to your cloud storage for the lowest price.
Try SoftNAS For better AWS Application Performance
SoftNAS can increase cloud application performance with 23x faster throughput, 18x better IOPs, and 24x less latency than other cloud storage solutions. It provides NAS capabilities suitable for the enterprise on AWS, Azure, VMware, and Red Hat Enterprise Linux (RHEL).
SoftNAS provides unified storage designed and optimized for high-performance, higher than normal I/O per second (IOPS), and data reliability and recoverability. It also increases storage efficiency through thin-provisioning, compression, and deduplication. See a SoftNAS DEMO