You can purchase different capacity disks from each variant (Example for Premium SSD Managed Disks, you can purchase from a P1 Disk with a 4GB capacity up to a P80 Disk with 32TB capacity). You will also want to note that as the capacity of the disks increase, so does the performance characteristics (throughput and IOPs) of the disk. And in some cases, you may need to purchase more capacity just to get the performance you need.
When planning your deployment with SoftNAS or other solutions, you will want to avoid configuring a mix of different size disks for a data pool in most cases to achieve more deterministic performance.
For example, if you decide you need 20TB of storage and you select 1 P70 disk (16TB) and 1 P50 disk (4TB) to create a 20TB data pool, you may notice strange performance characteristics. Why is this? It’s because your volume is split across a P70 disk with 750 MBs throughput and a P50 disk with 250 MBs throughput. If your application may run great when its accessing data from the P70, and they you may notice performance degrades when it accesses data from the P50 disk.
This is a reason to not get mixed up when using Azure Managed Disks, if you expect deterministic performance across your workload. Note, this is true across whatever type of Azure Manage Disk you use (Ultra, Premium SSD, Standard SSD or Standard HDD), mixing different size disks in a data pool can cause performance anomalies.
What’s my best option to prevent such anomalies? It depends on what problem you are trying to solve.
I’m looking for the best cost savings, and some inconsistent performance is acceptable:
For this example, let’s say you only need 5TB of capacity. In this case you can mix disk capacities, as long as the performance of the slowest disk meets your requirements (200MBs in the below example):
1 P30: 1 TB and 200MBs throughput
1 P50: 4 TB and 250MBs throughput
As long as you are OK that sometimes your workload will be capped by the lower performance of the P30 disk, this is the cheaper option. If your workload does not require greater than 200MBs performance, you should be fine.
I need consistent performance:
For this example, let’s say you need 10TB of capacity, but you know that you required about 350MBs of throughput. Mixing disks like below may cause issues because when accessing data from the P40 disk:
1 P40: 2 TB and 250MBs throughput
1 P60: 8 TB and 500MBs throughput
When accessing the data on the P40 disk, you will not get the required 350MBs through put.
So what can you do?
One option is round up your storage using only disks that provide the required throughput.
2 P60: 16 TB total and 500MBs throughput
But now you are paying for an extra 6TB.
A better solution is to leverage the aggregate throughput of a set of disks in a Pool. For example, instead of using 2 P60 disks, you may consider creating a Pool of 5 P40 disks and leverage the aggregate throughput of all 5 of the P40 disks. This not only can help you get better performance, but in some cases can be more cost effective.
2 P60 Disks:
Total Capacity: 16TB
Price: $1720.32
Aggregate Disk Throughput: 1000MBs
5 P40 Disks:
Total Capacity: 10TB
Price: $1177.60
Aggregate Disk Throughput: 1250MBs
Seems simple enough, but there are a few other factors to consider when planning your deployment.
Max Data Disks for your selected VM
If your analysis steers you towards an option to use more smaller capacity disks to get the performance you require, you will want to check the Max Data Disks allowed for your chosen Azure VM to run SoftNAS or other solution on. For example, a D2s_v3 VM only allows 4 data disks and would not allow you to connect 5 P40 disks as shown in the above example. In this case, you would either need to use a combination of larger capacity disks to reduce the disk count or select a larger VM with a higher Max Data Disk count. You can refer to Microsoft Azure documentation to review the Max Data Disk counts for VMs.
Max Throughput for your selected VM
The next factor to consider is the max throughput that your selected VM can provide. Just because the disk combination you selected can give you the performance you need, you need to ensure the VM you selected also allows enough throughput between your Data Disks and VM. You will want to refer to the Uncached Data Disk Performance number (throughput and IOPs) and other documentation related to burst and non-burst performance in the Microsoft Azure documentation for the selected VM to ensure that the VM you deploy does not throttle disk performance below your required performance.
When considering Azure Managed Disks for use with Buurst SoftNAS, you should consider:
How much storage capacity is required?
What are the performance requirements of your workload?
What VM choices do I have that enable the capacity and performance required?
Once you done a little homework, then it’s time to do some testing to verify that the choices you’ve made for your deployment meet your real-world requirements. You may find you have overestimated your requirements and can save some money with lower performance disks or VM or underestimated and need more performance from your storage or VM. This is where the cloud is great and allows you to reconfigure your deployment as needed.
Replacing EMC Isilon, VNX, and NetApp with AWS and Microsoft Azure cloud!
At Buurst, We have customers continually asking for solutions that will allow them to migrate from their existing on-premises storage systems to the Amazon AWS and Microsoft Azure cloud. We hear this often from EMC VNX and Isilon customers, and increasingly from NetApp customers as well.
The ask is usually prompted by receipt of the latest storage array maintenance bill or a more strategic decision to take action to close existing datacenters and replace them with the public cloud. In other cases, customers have many remote sites, offices, or factories where there’s simply not enough space to maintain all the data at the edge in smaller appliances. The convenience and appeal of the public cloud have become the obvious answer to these problems.
Customers want to trade out hardware ownership for the cloud subscription model and get out of the hardware management business.
Assessing the Environment
One of Isilon’s primary advantages that originally drove broad adoption is its scale-out architecture, which aggregates large pools of file storage with an ability to add more disk drives and storage racks as needed to scale what are effectively monolithic storage volumes. The Isilon has been a hugely successful workhorse for many years. As that gear comes of age, customers are faced with a fork in the road – continue to pay high maintenance costs in the forms of vendor license fees, replacing failing disks and ongoing expansion with more storage arrays overtime or take a different direction. In other cases, the aged equipment has reached its end of life and/or support period or it’s coming soon, so something must be done.
The options available today are pretty clear:
Forklift upgrade and replace the on-premises storage gear with new storage gear,
Shift storage and compute to a hyper-converged alternative, or
Migrate to the cloud and get out of the hardware business.
Increasingly, customers are ditching not just the storage gear but the entire data center at a much-increased pace. Interestingly, some are using their storage maintenance budget to fund migrating out of their datacenter into the cloud (and many reports they have money left over after that migration is completed).
This trend started as far back as 2013 for SoftNAS®, when The Street ditched their EMC VNX gear and used the 3-year maintenance budget to fund their entire cloud migration to AWS. You can read more about The Street’s migration here.
Like Isilon, the public cloud provides its own forms of scale-out, “bottomless” storage. The problem is that this cloud storage is not designed to be NFS or file-based but instead is block and object-based storage. The cloud providers are aware of this deficit, and they do offer some basic NFS and CIFS file storage services, which tend to be far too expensive (e.g., $3,600 per TB/year) and lack enterprise NAS features customers rely upon to protect their businesses and data and minimize cloud storage costs. These cloud file services sometimes deliver good performance but are also prone to unpredictable performance due to their shared storage architectures and the multi-tenant access overload conditions that plague them.
How Customers Replace EMC VNX Isilon and NetApp with SoftNAS®?
Buurst allows you to easily replace EMC VNX Isilon and NetApp with SoftNAS Cloud NAS.
As we see in the example below, SoftNAS Virtual NAS Appliance includes a “Lift and Shift data migration” feature that makes data migration into the cloud as simple as point, click, configure and go. This approach is excellent for up to 100 TB of storage, where data migration timeframes are reasonable over a 1 Gbps or 10 Gbps network link.
SoftNAS Lift and Shift feature continuously syncs data from the source NFS or CIFS mount points with the SoftNAS storage volumes hosted in the cloud, as shown below. Data migration over the wire is convenient for migration projects where data is constantly changing in production. It keeps both sides in sync throughout the workload migration process, making it faster and easier to move applications and dependencies from on-premises VM’s and servers into their new cloud-based counterparts.
In other cases, there could be petabytes of data that need to be migrated, much of that data being inactive data, archives, backups, etc. For large-scale migrations, the cloud vendors provide what we historically called “swing gear” – portable storage boxes designed to be loaded up with data, then shipped from one data center to another – in this case, it’s shipped to one of the hyper-scale cloud vendor’s regional datacenters, where the data gets loaded into the customer’s account. For example, AWS provides its Snowball appliance and Microsoft provides Azure DataBoxfor swing gear.
If the swing gear path is chosen, the data lands in the customer account in object storage (e.g., AWS S3 or Azure Blobs). Once loaded into the cloud, the SoftNAS team assists customers by bulk loading it into appropriate SoftNAS storage pools and volumes. Sometimes customers keep the same overall volume and directory structure – other times this is viewed as an opportunity to do some badly overdue reorganization and optimization.
Why Customers Choose SoftNAS vs. Alternatives
SoftNAS provides an ideal choice for the customer who is looking to host data in the public cloud in that it delivers the most cost-effective storage management available. SoftNAS is able to deliver the lowest costs for many reasons, including:
No Storage Tax – Buurst SoftNAS does not charge for your storage capacity. You read that right. You get unlimited storage capacity and only pay for additional performance.
Unique Storage Block Tiering – SoftNAS provides multi-level, automatic block tiering that balances peak performance on NVMe and SSD tiers, coupled with low-cost bulk storage for inactive or lazy data in HDD block storage.
Superior Storage Efficiencies – SoftNAS includes data compression and data deduplication, reducing the actual amount of cloud block storage required to host your file data.
The net result is customers save up to 80% on their cloud storage bills by leveraging SoftNAS’s advanced cost savings features, coupled with unlimited data capacity.
Summary and Next Steps
Isilon is a popular, premises-based file server that has served customers well for many years. VNX is the end of life. NetApp 7-mode appliances are long in the tooth with the end of full NetApp 7-mode support on 31 December 2020 (6 months from this posting). Customers running other traditional NAS appliances from IBM®, HP, Quantum, and others are in similar situations.
Since 2013, as the company that created the Cloud NAS category, Buurst SoftNAS has helped migrate thousands of workloads and petabytes of data from on-premises NAS filers of every kind across 39 countries globally. So you can be confident that you’re in good company with the cloud data performance experts at Buurst guiding your way and migrating your data and workloads into the cloud.
To learn more, register for a Free Consultation with one of our cloud experts. To get a free cost estimate or schedule a free cloud migration assessment, pleasecontact the Buurst team.
7 Cloud File Data Management Pitfalls and How to Avoid Them
There are many compelling reasons to migrate applications and workloads to the cloud, from scalability and agility to easier maintenance. But anytime IT systems or applications go down it can prove incredibly costly to the business. Downtime costs between $100,000 to $450,000 per hour, depending upon the applications affected. And these costs do not account for the political costs or damage to a company’s brand and image with its customers and partners, especially if the outage becomes publicly visible and newsworthy.
Cloud File Data Management Pitfalls
“Through 2022, at least 95% of cloud security failures will be the customer’s fault,” says Jay Heiser, research vice president at Gartner. If you want to avoid being in that group, then you need to know the pitfalls to avoid. To that end here are seven traps that companies often fall into and what can be done to avoid them.
1. No data-protection strategy
It’s vital that your company data is safe at rest and in-transit. You need to be certain that it’s recoverable when (not if) the unexpected strikes. The cloud is no different than any other data center or IT infrastructure in that it’s built on hardware that will eventually fail. It’s managed by humans, who are prone to an occasional error, which is what typically has caused most major cloud outages over the past 5 years that I’ve seen on a large scale.
Consider the threats of data corruption, ransomware, accidental data deletion due to human error, or a buggy software update, coupled with unrecoverable failures in cloud infrastructure. If the worst should happen, you need a coherent, durable data protection strategy. Put it to the test to make sure it works.
Most native cloud file services provide limited data protection (other than replication) and no protection against corruption, deletion or ransomware. For example, if your data is stored in EFS on AWS® and files or a filesystem get deleted, corrupted or encrypted and ransomed, who are you going to call? How will you get your data back and business restored? If you call AWS Support, you may well get a nice apology, but you won’t get your data back. AWS and all the public cloud vendors provide excellent support, but they aren’t responsible for your data (you are).
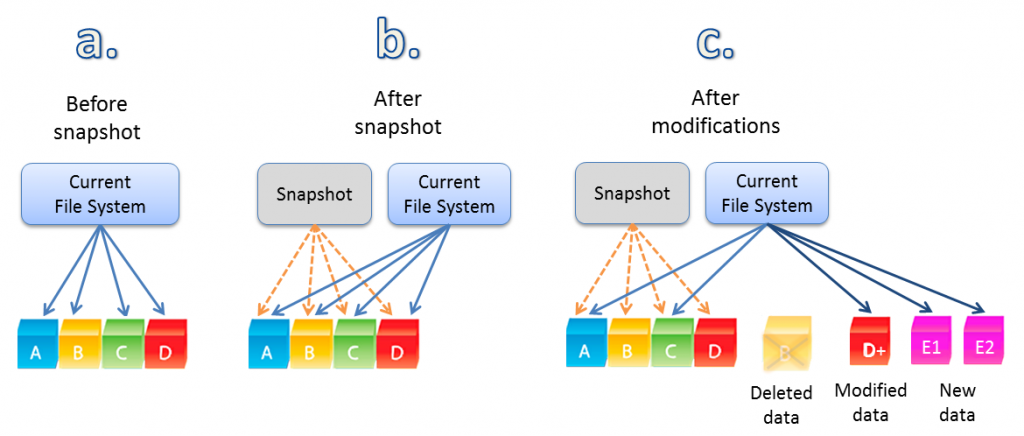
As shown below, a Cloud NAS with a copy-on-write (COW) filesystem, like ZFS, does not overwrite data. In this oversimplified example, we see data blocks A – D representing the current filesystem state. These data blocks are referenced via filesystem metadata that connects a file/directory to its underlying data blocks, as shown in a. As a second step, we see a Snapshot was taken, which is simply a copy of the pointers as shown in b. This is how “previous versions” work, like the ability on a Mac to use Time Machine to roll back and recover files or an entire system to an earlier point in time.
Anytime we modify the filesystem, instead of a read/modify/write of existing data blocks, we see new blocks are added in c. And we also see block D has been modified (copied, then modified and written), and the filesystem pointers now reference block D+, along with two new blocks E1 and E2. And block B has been “deleted” by removing its filesystem pointer from the current filesystem tip, yet the actual block B continues to exist unmodified as it’s referenced by the earlier Snapshot.
Copy on write filesystems use Snapshots to support rolling back in time to before a data loss event took place. In fact, the Snapshot itself can be copied and turned into what’s termed a “Writable Clone”, which is effectively a new branch of the filesystem as it existed at the time the Snapshot was taken. A clone contains a copy of all the data block pointers, not copies of the data blocks themselves.
Enterprise Cloud NAS products use COW filesystems and then automate management of scheduled snapshots, providing hourly, daily and weekly Snapshots. Each Snapshot provides a rapid means of recovery, without rolling a backup tape or other slow recovery method that can extend an outage by many hours or days, driving the downtime costs through the roof.
With COW, snapshots, and writable clones, it’s a matter of minutes to recover and get things back online, minimizing the outage impact and costs when it matters most. Use a COW filesystem that supports snapshots and previous versions. Before selecting a filesystem, make sure you understand what data protection features it provides. If your data and workload are business-critical, ensure the filesystem will protect you when the chips are down (you may not get a second chance if your data is lost and unrecoverable).
2. No data-security strategy
It’s common practice for the data in a cloud data center to be comingled and collocated on shared devices with countless other unknown entities. Cloud vendors may promise that your data is kept separately, but regulatory concerns demand that you make certain that nobody, including the cloud vendor, can access your precious business data.
Think about access that you control (e.g., Active Directory), because basic cloud file services often fail to provide the same user authentication or granular control as traditional IT systems. The Ponemon Institute puts the average global cost of a data breach at $3.92 million. You need a multi-layered data security and access control strategy to block unauthorized access and ensure your data is safely and securely stored in encrypted form wherever it may be.
Look for NFS and CIFS solutions that provide encryption for data both at rest and in flight, along with granular access control.
3. No rapid data-recovery strategy
With storage snapshots and previous versions managed by dedicated NAS appliance, rapid recovery from data corruption, deletion or other potentially catastrophic events is possible. This is a key reason that there are billions of dollars worth of NAS applications hosting on-premises data today.
But few cloud-native storage systems provide snapshotting or offer easy rollback to previous versions, leaving you reliant on current backups. And when you have many terabytes or more of filesystem data, restoring from a backup will take many hours to days. Obviously, restores from backups are not a rapid recovery strategy – it should be the path of last resort because it’s so slow and going to extend the outage by hours to days and the losses potentially into six-figures or more.
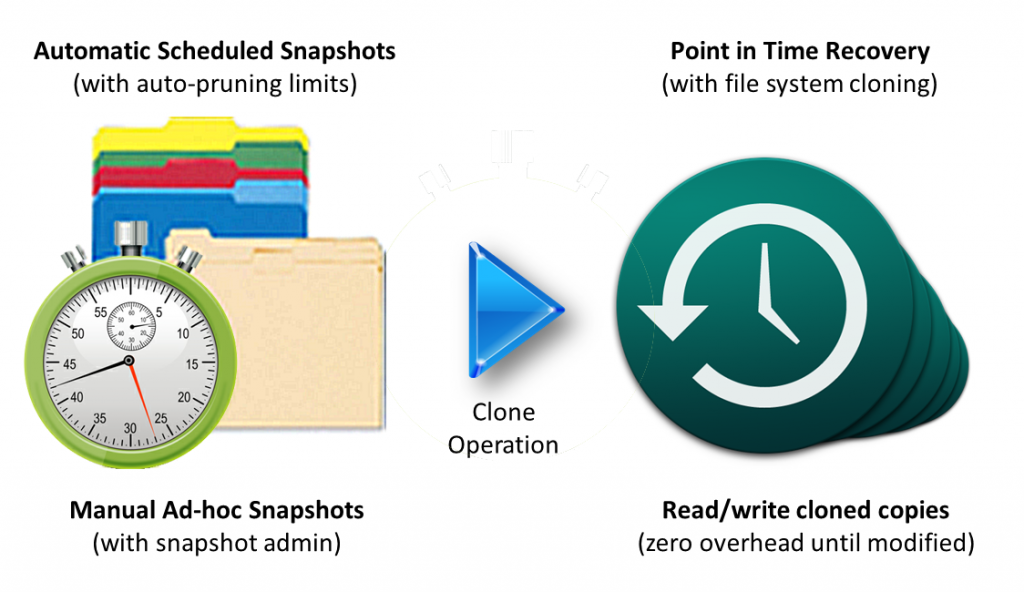
You need flexible, instant storage snapshots and writable clones that provide rapid recovery and rollback capabilities for business-critical data and applications. Below we see previous version snapshots represented as colored folders, along with auto pruning over time. With the push of a button, an admin can clone a snapshot instantly, creating a writable clone copy of the entire filesystem that shares all the same file data blocks using a new set of cloned pointers. Changes made to the cloned filesystem do not alter the original snapshot data blocks; instead, new data blocks are written via the COW filesystem semantics, as usual, keeping your data fully protected.
Ensure your data recovery strategy includes “instant snapshots” and “writable clones” using a COW filesystem. Note that what cloud vendors typically call snapshots are actually deep copies of disks, not consistent instant snapshots, so don’t be confused as they’re two totally different capabilities.
4. No data-performance strategy
Shared, multi-tenant infrastructure often leads to unpredictable performance. We hear the horror stories of unpredictable performance from customers all the time. Customers need “sustained performance” that can be counted on to meet SLAs.
Most cloud storage services lack the facilities to tune performance, other than adding more storage capacity, along with corresponding unnecessary costs. Too many simultaneous requests, network overloads, or equipment failures can lead to latency issues and sluggish performance in the shared filesystem services offered by the cloud vendors.
Look for a layer of performance control for your file data that enables all your applications and users to get the level of responsiveness that’s expected. You should also ensure that it can readily adapt as demand and budgets grow over time.
Cloud NAS filesystem products provide the flexibility to quickly adjust the right blend of (block) storage performance, memory for caching read-intensive workloads, and network speeds required to push the data at the optimal speed. There are several available “tuning knobs” to optimize the filesystem performance to best match your workload’s evolving needs, without overprovisioning storage capacity or costs.
Look for NFS and CIFS filesystems that offer the full spectrum of performance tuning options that keep you in control of your workload’s performance over time, without breaking the bank as your data storage capacity ramps and accelerates.
5. No data-availability strategy
Hardware fails, people commit errors, and occasional outages are an unfortunate fact of life. It’s best to plan for the worst, create replicas of your most important data and establish a means to quickly switch over whenever sporadic failure comes calling.
Look for a cloud or storage vendor willing to provide an SLA guarantee that matches your business needs and supports the SLA you provide to your customers. Where necessary create a failsafe option, with a secondary storage replica to ensure your applications do not experience any outage and instead a rapid HA failover occurs instead of an outage.
In the cloud, you can get 5-9’s high availability from solutions that replicate your data across two availability zones; i.e., 5 minutes or less of unplanned downtime per year. Ask your filesystem vendor to provide a copy of their SLA and uptime guarantee to ensure it’s aligned with the SLAs your business team requires to meet its own SLA obligations.
6. No multi-cloud interoperability strategy
As many as 90% of organizations will adopt a hybrid infrastructure by 2020, according to Gartner analysts. There are plenty of positive driving forces as companies look to optimize efficiency and control costs, but you must properly assess your options and the impact on your business. Consider the ease with which you can switch vendors in the future and any code that may have to be rewritten. Cloud platforms entangle you with proprietary APIs and services, but you need to keep your data and applications multi-cloud capable to stay agile and preserve choice.
You may be delighted with your cloud platform vendor today and have no expectations of making a change, but it’s just a matter of time until something happens that causes you to need a multi-cloud capability. For example, your company acquires or merges with another business that brings a different cloud vendor to the table and you’re faced with the need to either integrate or interoperate. Be prepared as most businesses will end up in a multi-cloud mode of operation.
7. No disaster-recovery strategy
A simple mistake where a developer accidentally pushes a code drop into a public repository and forgets to remove the company’s cloud access keys from the code could be enough to compromise your data and business. It definitely happens. Sometimes the hackers who gain access are benign, other times they are destructive and delete things. In the worst case, everything in your account could be affected.
Maybe your provider will someday be hacked and lose your data and backups. You are responsible and will be held accountable, even though the cause is external. Are you prepared? How will you respond to such an unexpected DR event?
It’s critically important to keep redundant, offsite copies of everything required to fully restart your IT infrastructure in the event of a disaster or full-on hacker attack break-in.
The temptation to cut corners and keep costs down with data management is understandable, but it is dangerous, short-term thinking that could end up costing you a great deal more in the long run. Take the time to craft the right DR and backup strategy and put those processes in place, test them periodically to ensure they’re working, and you can mitigate these risks.
For example, should your cloud root account somehow get compromised, is there a fail-safe copy of your data and cloud configuration stored in a second, independent cloud (or at least a different cloud account) you can fall back on? DR is like an insurance policy – you only get it to protect against the unthinkable, which nobody expects will happen to them… until it does. Determine the right level of DR preparedness and make those investments. DR costs should not be huge in the cloud since most everything (except the data) is on-demand.
Conclusions
We have seen how putting the right data management plans in place ahead of an outage will make the difference between a small blip on the IT and business radars vs. a potentially lengthy outage that costs hundreds of thousands to millions of dollars – and more when we consider the intangible losses and career impacts that can arise. Most businesses that have operated their own data centers know these things, but are these same measures being implemented in the cloud?
The cloud offers us many shortcuts to quickly get operational. After all, the cloud platform vendors want your workloads running and billing hours on their cloud as soon as possible. Unfortunately, choosing naively upfront may get your workloads migrated faster and up and running on schedule, but in the long run, cost you and your company dearly.
Use the above cloud file data management strategies to avoid the 7 most common pitfalls. Learn more about howSoftNAS Cloud NAS helps you address all 7 of these data management areas.
Meeting Cloud Storage Cost and Performance Goals – Harder than You Think
According to Gartner, by 2025 80% of enterprises will shut down their traditional data centers. Today, 10% already have. We know this is true because we have helped thousands of these businesses migrate workloads and business-critical data from on-premises data centers into the cloud since 2013. Most of those workloads have been running 24 x 7 for 5+ years. Some of them have been digitally transformed (code for “rewritten to run natively in the cloud”).
The biggest challenge in adopting the cloud isn’t the technology shift – it’s finding the right balance of storage cost vs performance and availability that justifies moving data to the cloud. We all have a learning curve as we migrate major workloads into the cloud. That’s to be expected as there are many choices to make – some more critical than others.
Applications in the cloud
Many of our largest customers operate mission-critical, revenue-generating applications in the cloud today. Business relies on these applications and their underlying data for revenue growth, customer satisfaction, and retention. These systems cannot tolerate unplanned downtime. They must perform at expected levels consistently… even under increasingly heavy loads, unpredictable interference from noisy cloud neighbors, occasional cloud hardware failures, sporadic cloud network glitches, and other anomalies that just come with the territory of large-scale data center operations.
In order to meet customer and business SLAs, cloud-based workloads must be carefully designed. At the core of these designs is how data will be handled. Choosing the right file service component is one of the critical decisions a cloud architect must make.
Application performance, costs, and availability
For customers to remain happy, application performance must be maintained. Easier said than done when you no longer control the IT infrastructure in the cloud.
So how does one negotiate these competing objectives around cost, performance, and availability when you no longer control the hardware or virtualization layers in your own data center? And how can these variables be controlled and adapted over time to keep things in balance? In a word – control. You must correctly choose where to give up control and where to maintain control over key aspects of the infrastructure stack supporting each workload.
One allure of the cloud is that it’s (supposedly) going to simplify everything into easily managed services, eliminating the worry about IT infrastructure forever. For non-critical use cases, managed services can, in fact, be a great solution. But what about when you need to control costs, performance, and availability?
Unfortunately, managed services must be designed and delivered for the “masses”, which means tradeoffs and compromises must be made. And to make these managed services profitable, significant margins must be built into the pricing models to ensure the cloud provider can grow and maintain them.
In the case of public cloud-shared file services like AWS Elastic File System (EFS) and Azure NetApp Files (ANF), performance throttling is required to prevent thousands of customer tenants from overrunning the limited resources that are actually available. To get more performance, you must purchase and maintain more storage capacity (whether you actually need that add-on storage or not). And as your storage capacity inevitably grows, so do the costs. And to make matters worse, much of that data is actually inactive most of the time, so you’re paying for data storage every month that you rarely if ever even access. And the cloud vendors have no incentive to help you reduce these excessive storage costs, which just keep going up as your data continues to grow each day.
After watching this movie play out with customers for many years and working closely with the largest to smallest businesses across 39 countries, At Buurst™. we decided to address these issues head-on. Instead of charging customers what is effectively a “storage tax” for their growing cloud storage capacity, we changed everything by offering Unlimited Capacity. That is, with SoftNAS® you can store an unlimited amount of file data in the cloud at no extra cost (aside from the underlying cloud block and object storage itself).
SoftNAS has always offered both data compression and deduplication, which when combined typically reduces cloud storage by 50% or more. Then we added automatic data tiering, which recognizes inactive and stale data, archiving it to less expensive storage transparently, saving up to an additional 67% on monthly cloud storage costs.
Just like when you managed your file storage in your own data center, SoftNAS keeps you in control of your data and application performance. Instead of turning control over to the cloud vendors, you maintain total control over the file storage infrastructure. This gives you the flexibility to keep costs and performance in balance over time.
To put this in perspective, without taking data compression and deduplication into account yet, look at how Buurst SoftNAS costs compare:
SoftNAS vs NetApp ONTAP, Azure NetApp Files, and AWS EFS
These monthly savings really add up. And if your data is compressible and/or contains duplicates, you will save up to 50% more on cloud storage because the data is compressed and deduplicated automatically for you.
Fortunately, customers have alternatives to choose from today:
GIVE UP CONTROL – use cloud file services like EFS or ANF, pay for both performance and capacity growth, and give up control over your data or ability to deliver on SLAs consistently
KEEP CONTROL – of your data and business with Buurst SoftNAS, and balance storage costs, and performance to meet your SLAs and grow more profitably.
Sometimes cloud migration projects are so complex and daunting that it’s advantageous to just take shortcuts to get everything up and running and operational as a first step. We commonly see customers choose cloud file services as an easy first stepping stone to a migration. Then these same customers proceed to the next step – optimizing costs and performance to operate the business profitably in the cloud and they contact Buurst to take back control, reduce costs, and meet SLAs.
As you contemplate how to reduce cloud operating costs while meeting the needs of the business, keep in mind that you face a pivotal decision ahead. Either keep control or give up control of your data, its costs, and performance. For some use cases, the simplicity of cloud file services is attractive and the data capacity is small enough and performance demands low enough that the convenience of files-as-a-service is the best choice. As you move business-critical workloads where costs, performance and control matter, or the datasets are large (tens to hundreds of terabytes or more), keep in mind that Buurst never charges you a storage tax on your data and keeps you in control of your business destiny in the cloud.
At Buurst, we’re thinking about your data differently, and that means it’s now possible to bring all your data to the cloud and make it cost effective. We know data is the DNA of your business, which is why we’re dedicated to getting you the best performance possible, with the best cloud economics.
When you approach a traditional storage vendor, regardless of your needs, they will all tell you the same thing: buy more storage. Why is this? These vendors took their on-premises storage pricing models to the cloud with them, but they add unnecessary constraints, driving organizations down slow, expensive paths. These legacy models sneak in what we refer to as a Storage Tax. We see this happen in a number of ways:
Tax on data: when you pay for storage to a cloud NAS vendor for the storage you’ve already paid for
Tax on performance: when you need more performance, they make you buy more storage
Tax on capabilities: when you pay a premium on storage for NAS capabilities
So how do we eliminate the Storage Tax?
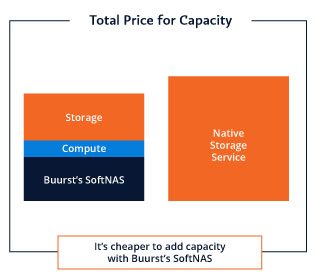
Buurst unbundles the cost of storage and performance, meaning you can add performance, without spinning up new storage and vice versa. As shown in the diagrams below, instead of making you buy more storage when you need more performance, Buurst’s pricing model allows you to add additional SoftNAS instances and compute power for the same amount of data. On the opposite side, if you need to increase your capacity, Buurst allows you to attach as much storage behind it as needed, without increasing performance levels.
Why are we determined to eliminate the StorageTax?
At Buurst, our focus is on providing you with the best performance, availability, cost management, migration, and control –not how much we can charge you for your data. We’ve carried this through our pricing model to ensure you’re getting the best all-up data experience on the cloud of your choice. This means ensuring your storage prices remain lower than the competition.
Looking at the below figures illustrates this point further:
NetApp ONTAP™ Cloud Storage
10TB
Buurst’s SoftNAS
$1,992
ONTAP
$4,910
%
NetApp Azure NetApp Files
8TB
Buurst’s SoftNAS
$1,389
ANF
$2,410
%
AWS Elastic File Services
8TB
Buurst’s SoftNAS
$1,198
AWS EFS
$2,457
%
AWS Elastic File Services
512TB
Buurst’s SoftNAS
$28,798
AWS EFS
$157,286
%
These figures reflect full-stack costs, including computing instances, storage, and NAS capabilities, in a high availability configuration, with the use of SmartTiers, Buurst’s dynamic block-based storage tiering. With 10TB of data, SoftNAS customers save up to 60% compared to NetApp ONTAP. And at 8TB of data, when compared with Azure NetApp Files and Amazon EFS, customers see cost savings of 42% and 51%, respectively. The savings can continue to grow as you add more data over time. When compared to Amazon EFS, SoftNAS users can save up to 82%at the 512TB level. Why is this? Because we charge a fixed fee, meaning the more data you have, the more cost-effective Buurst will be.
But we don’t just offer a competitive pricing model. Buurst customers also experience benefits around:
Data performance: Fast enough to handle the most demanding workloads with up to 1 million IOPS on AWS
Data migration: Point and click file transfers to with speeds up to 200% faster than TCP/IP over high latency and noisy networks
Data availability: Cross-zone high availability with up to 99.999% uptime, asynchronous replication, and EBS snapshots
Data control and security: Enterprise NAS capabilities in the cloud including at-rest and in-flight data encryption.
At Buurst, we understand that you need to move fast, and so does your data. Our nimble, cost-effective data migration and performance management solution opens new opportunities and capabilities that continually prepare you for success.
Get all the tools you need so day one happens faster and you can be amazing on day two, month two, and even year two. We make your cloud decisions work for you – and that means providing you data control, data performance, cost-management with storage tiering, and security.
To learn how Buurst can help you manage costs on the cloud, download our eBook:
Recently, a Buurst’s SoftNAS customer that provides a sales enablement and readiness platform evaluated their current on-premises storage environment. They had growing concerns regarding whether or not their existing solution could support the large volumes of data their applications needed. The customer had Isilon storage in their datacenter and a dedicated remote Disaster Recovery (DR) datacenter with another Isilon storing 100 TB of data. With the growth of their data-intensive applications, the company predicted the dedicated DR site would be at full capacity within two years. This pushed them to evaluate cloud-based solutions that wouldn’t require them to continue purchasing and maintaining new hardware.
Buurst SoftNAS Cloud NAS Storage quickly became the ideal choice as it could support the petabytes of file storage they needed, allowing them to dynamically tier their storage by moving aging data to slower, less expensive storage. This new capability would solve their need for 100 TB of storage, as well as allow them to pay only for the services they used while also eliminating the need to pay for and maintain physical datacenters, network-attached storage, and storage area network (SAN) appliances.
By moving data to SoftNAS virtual cloud NAS, the customer was able to quickly build a cloud-based DR platform with 100 TB of storage attached to it. Because of the successful disaster recovery platform, the company plans to make SoftNAS their primary storage solution, leveraging enterprise-class features like bottomless scalable storage and highly available clustering, allowing them to take full advantage of what the cloud has to offer.
Cloud-enable your Isilon data with SoftNAS Cloud NAS Storage.
Data volumes are increasing at rates that are virtually impossible to keep up with using on-premises storage. If you’re leveraging an Isilon storage solution, you’re likely looking for ways to expand your storage capacity quickly, securely, and with the lowest cost. When considering your data storage strategy, ask yourself a few key questions:
Do I have the physical space, power, and cooling for more storage?
Do I have CapEx to purchase more storage?
Do I want to build more data centers for more storage?
On-premises storage solutions can limit your organization from truly unlocking modern data analytics and AI/ML capabilities. The cost and upkeep required to maintain on-premises solutions prevent your teams from exploring ways to position your business for future growth opportunities. This push for modernization is often a driving factor for organizations to evaluate cloud-based solutions, which comes with its own considerations:
Do I have a reliable and fast connection to the internet?
How can I control the cost of cloud storage?
How can I continuously sync live data?
With SoftNAS running on the cloud you can:
Make cloud backups run up to 400% faster at near-block-level performance with object storage pricing, resulting in substantial cost savings. SoftNAS optimizes data transfer to cloud object storage, so it’s as fast as possible without exceeding read/write capabilities.
Automate storage tiering policies to reduce the cost of cloud storage by moving aged data from more expensive, high-performance block storage to less expensive, slower storage, reducing cloud storage costs by up to 67%.
Continuously keep content up to date when synchronizing data to the cloud of your choice by reliably running bulk data transfer jobs with automatic restart/suspend/resume.
Get started by pointing SoftNAS to existing Isilon shared storage volumes, select your cloud storage destination, and immediately begin moving your data. It’s that easy.
Find out more about how SoftNAS enables you to:
Trade CapEx for OpEx
Seamlessly and securely migrate live production data
Control the cost of cloud storage
Continuously sync live data to the cloud
Do more with Isilon data with the cloud Cloud enable your Isilon data with SoftNAS. Maximize the value of your Isilon data with the cloud-Enable services for your Isilon data.
Buurst SoftNAS allows you to modernize your data to unlock insights with advanced analytics, enable multi-cloud deployments with a cloud-agnostic solution, and utilize cloud-native architectures to achieve cloud-scale. Maximize control of your cloud data by providing high availability, simplified security, and enterprise-grade tools that extend capabilities across any cloud. Realize your cloud strategy by providing cost-effective cloud storage, transform your disaster recovery solution to the cloud without the constraints of legacy hardware,