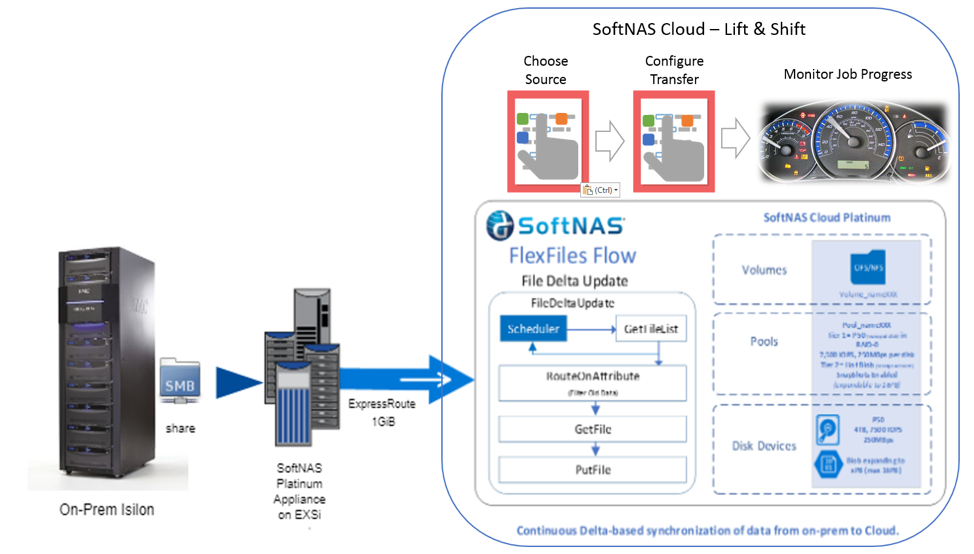
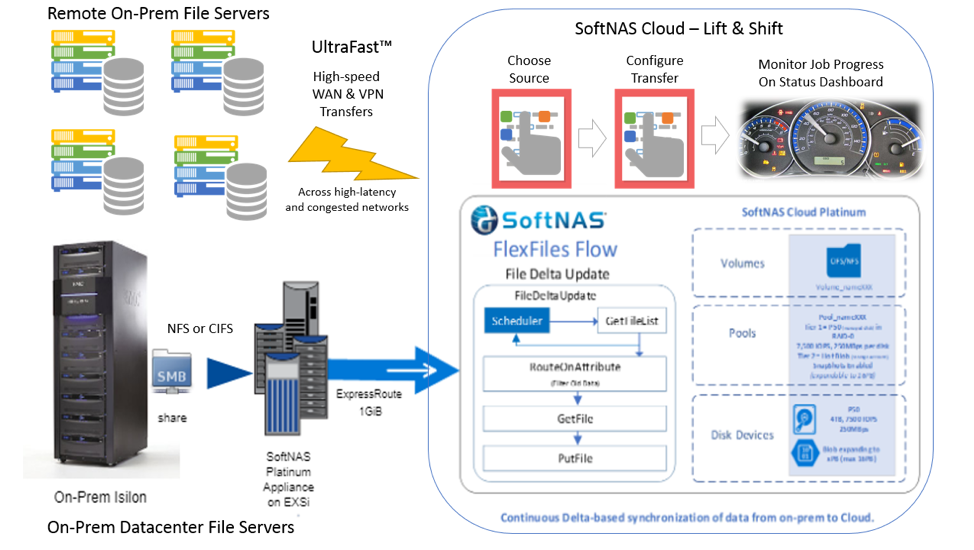
How to Maintain Control of Your Core in the Cloud
For the past 7 years, Buurst’s SoftNAS has helped customers in 35 countries globally to successfully migrate thousands of applications and petabytes of data out of on-premises data centers into the cloud. Over that time, we’ve witnessed a major shift in the types of applications and the organizations involved.
The move to the cloud started with simpler, low-risk apps and data until companies became comfortable with cloud technologies. Today, we see companies deploying their core business and mission-critical applications to the cloud, along with everything else as they evacuate their data centers and colors at a breakneck pace. At the same time, the mix of players has also shifted from early adopters and DevOps to a blend that includes mainstream IT.
The major cloud platforms make it increasingly easy to leverage cloud services, whether building a new app, modernizing apps, or migrating and rehosting the thousands of existing apps large enterprises run today.
Whatever cloud app strategy is taken, one of the critical business and management decisions is where to maintain control of the infrastructure and where to turn control over to the platform vendor or service provider to handle everything, effectively outsourcing those components, apps, and data.
Migrating to the cloud
So how can we approach these critical decisions to either maintain control or outsource to others when migrating to the cloud? This question is especially important to carefully consider as we move our most precious, strategic, and critical data and application business assets into the cloud.
One approach is to start by determining whether the business, applications, data and underlying infrastructure are “core” vs. “context”, a distinction popularized by Geoffrey Moore in Dealing with Darwin.
He describes Core and Context as a distinction that separates the few activities that a company does that create true differentiation from the customer viewpoint (CORE) from everything else that a company needs to do to stay in business (CONTEXT).
Core elements of a business are the strategic areas and assets that create differentiation and drive value and revenue growth, including innovation initiatives.
Context refers to the necessary aspects of the business that are required to “keep the lights on”, operate smoothly, meet regulatory and security requirements and run the business day-to-day; e.g., email should be outsourced unless you are in the email hosting business (in which case it’s core).
It’s important to maintain direct control of the core elements of the business, focusing employees and our best and brightest talents on these areas. In the cloud, core elements include innovation, business-critical, and revenue-generating applications and data, which remain central to the company’s future.
Certain applications and data that comprise business context can and should be outsourced to others to manage. These areas remain important as the business cannot operate without them, but they do not warrant our employees’ constant attention and time in comparison to the core areas.
The core demands the highest performance levels to ensure applications run fast and keep customers and users happy. It also requires the ability to maintain SLAs around high availability, RTO and RPO objectives to meet contractual obligations. Core demands the flexibility and agility to quickly and readily adapt as new business demands, opportunities, and competitive threats emerge.
Many of these same characteristics are also important to business context areas as well, but not as critical as the context that can simply be moved around from one outsourced vendor to another as needed.
Increasingly, we see business-critical, core applications and data migrating into the cloud. These customers demand control of their core business apps and data in the cloud, as they did on-premises. They are accustomed to managing key infrastructure components, like the network-attached storage (NAS) that hosts the company’s core data assets and powers the core applications. We see customers choose a dedicated Cloud NAS Filer that keeps them in control of their core in the cloud.
Example core apps include revenue-generating e-discovery, healthcare imaging, 3D seismic oil and gas exploration, financial planning, loan processing, video rental, and more. The most common theme we see across these apps is that they drive core subscription-based SaaS business revenue. Increasingly, we see both file and database data being migrated and hosted atop of the Cloud NAS, especially SQL Server.
For these core business use cases, maintaining control over the data and the cloud storage is required to meet performance and availability SLAs, security and regulatory requirements, and to achieve the flexibility and agility to quickly adapt and grow revenues. The dedicated Cloud NAS meets the core business requirements in the cloud, as it has done on-premises for years.
We also see many less critical business context data being outsourced and stored in cloud file services such as Azure Files and AWS EFS. In other cases, the Cloud NAS’s ability to handle both core and context use cases is appealing. For example, leveraging both SSD for performance and object storage for lower-cost bulk storage and archival with unified NFS and CIFS/SMB makes the Cloud NAS more attractive in certain cases.
There are certainly other factors to consider when choosing where to draw the lines between control and outsourcing applications, infrastructure, and data in the cloud.
Ultimately, understanding which applications and data are core vs context to the business can help architects and management frame the choices for each use case and business situation, applying the right set of tools for each of these jobs to be done in the cloud.
Check Also:
Successful cloud data management strategy
When will your company ditch its data centers?
Migrate Workloads and Applications to the Cloud
When it’s time to close your data center and how to do it safely












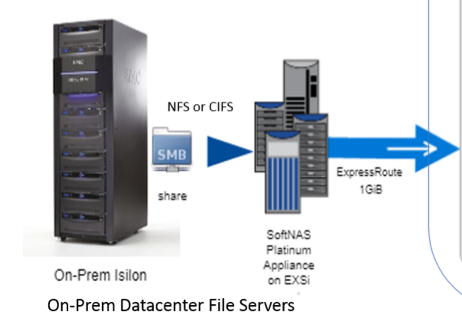
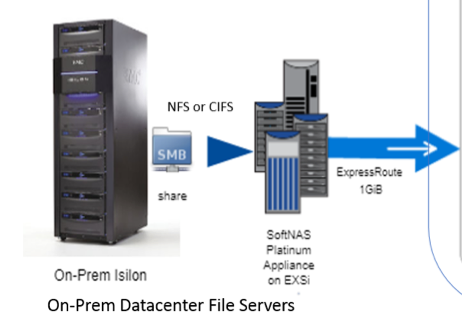
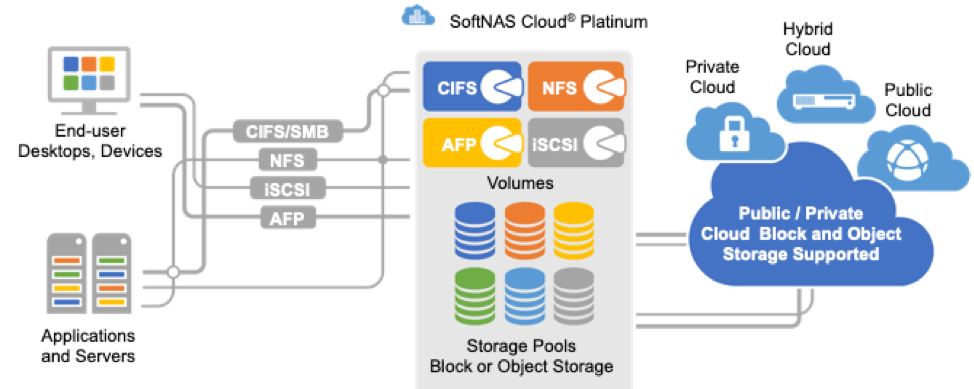 SoftNAS leverages the cloud providers’ block and object storage
SoftNAS leverages the cloud providers’ block and object storage