How can you leverage the cloud to manage the costs of your Isilon data while you grow?
Recently, a Buurst’s SoftNAS customer that provides a sales enablement and readiness platform evaluated their current on-premises storage environment. They had growing concerns regarding whether or not their existing solution could support the large volumes of data their applications needed. The customer had Isilon storage in their datacenter and a dedicated remote Disaster Recovery (DR) datacenter with another Isilon storing 100 TB of data. With the growth of their data-intensive applications, the company predicted the dedicated DR site would be at full capacity within two years. This pushed them to evaluate cloud-based solutions that wouldn’t require them to continue purchasing and maintaining new hardware.
Buurst SoftNAS Cloud NAS Storage quickly became the ideal choice as it could support the petabytes of file storage they needed, allowing them to dynamically tier their storage by moving aging data to slower, less expensive storage. This new capability would solve their need for 100 TB of storage, as well as allow them to pay only for the services they used while also eliminating the need to pay for and maintain physical datacenters, network-attached storage, and storage area network (SAN) appliances.
By moving data to SoftNAS virtual cloud NAS, the customer was able to quickly build a cloud-based DR platform with 100 TB of storage attached to it. Because of the successful disaster recovery platform, the company plans to make SoftNAS their primary storage solution, leveraging enterprise-class features like bottomless scalable storage and highly available clustering, allowing them to take full advantage of what the cloud has to offer.
Cloud-enable your Isilon data with SoftNAS Cloud NAS Storage.
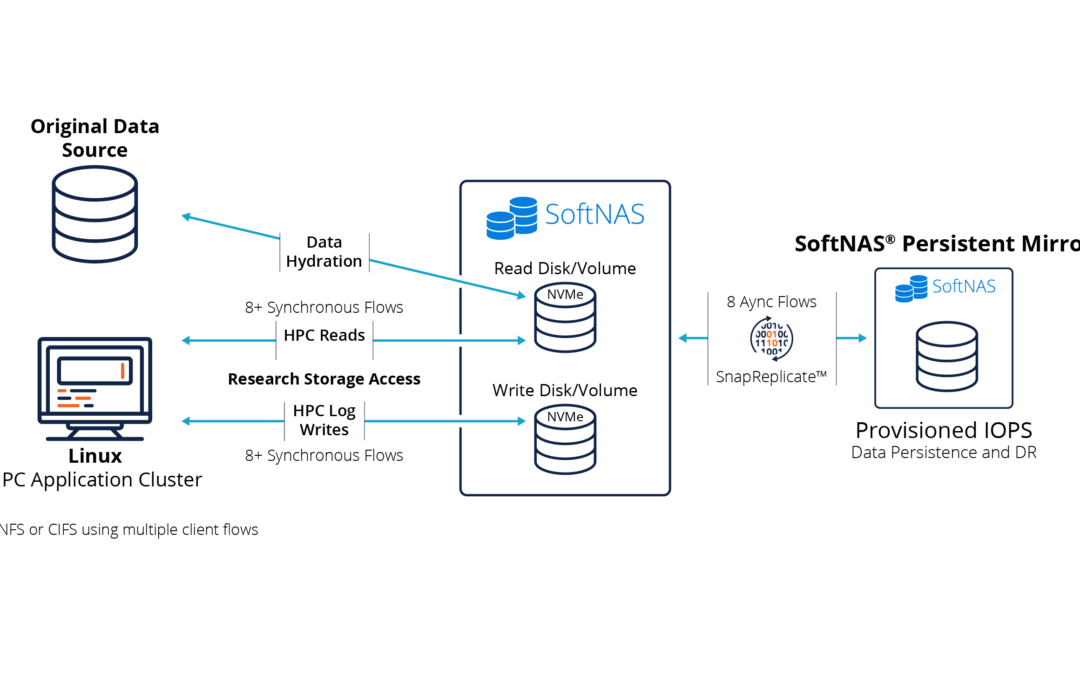
Data volumes are increasing at rates that are virtually impossible to keep up with using on-premises storage. If you’re leveraging an Isilon storage solution, you’re likely looking for ways to expand your storage capacity quickly, securely, and with the lowest cost. When considering your data storage strategy, ask yourself a few key questions:
- Do I have the physical space, power, and cooling for more storage?
- Do I have CapEx to purchase more storage?
- Do I want to build more data centers for more storage?
On-premises storage solutions can limit your organization from truly unlocking modern data analytics and AI/ML capabilities. The cost and upkeep required to maintain on-premises solutions prevent your teams from exploring ways to position your business for future growth opportunities. This push for modernization is often a driving factor for organizations to evaluate cloud-based solutions, which comes with its own considerations:
- Do I have a reliable and fast connection to the internet?
- How can I control the cost of cloud storage?
- How can I continuously sync live data?
With SoftNAS running on the cloud you can:
- Make cloud backups run up to 400% faster at near-block-level performance with object storage pricing, resulting in substantial cost savings. SoftNAS optimizes data transfer to cloud object storage, so it’s as fast as possible without exceeding read/write capabilities.
- Automate storage tiering policies to reduce the cost of cloud storage by moving aged data from more expensive, high-performance block storage to less expensive, slower storage, reducing cloud storage costs by up to 67%.
- Continuously keep content up to date when synchronizing data to the cloud of your choice by reliably running bulk data transfer jobs with automatic restart/suspend/resume.
Get started by pointing SoftNAS to existing Isilon shared storage volumes, select your cloud storage destination, and immediately begin moving your data. It’s that easy.
Find out more about how SoftNAS enables you to:
- Trade CapEx for OpEx
- Seamlessly and securely migrate live production data
- Control the cost of cloud storage
- Continuously sync live data to the cloud
Do more with Isilon data with the cloud Cloud enable your Isilon data with SoftNAS. Maximize the value of your Isilon data with the cloud-Enable services for your Isilon data.
Buurst SoftNAS allows you to modernize your data to unlock insights with advanced analytics, enable multi-cloud deployments with a cloud-agnostic solution, and utilize cloud-native architectures to achieve cloud-scale. Maximize control of your cloud data by providing high availability, simplified security, and enterprise-grade tools that extend capabilities across any cloud. Realize your cloud strategy by providing cost-effective cloud storage, transform your disaster recovery solution to the cloud without the constraints of legacy hardware,
Check Also:
Consolidate Your Files in the Cloud
Migrating Existing Applications to AWS
Replacing EMC Isilon, VNX & NetApp with AWS & Azure