We’ve seen a lot of interest from our customers in building an AWS hybrid cloud architecture. Maybe you’re just a little bit too hesitant to move your entire infrastructure to the public cloud, so we’ll be talking about how to build a hybrid cloud that gives you the best of both worlds.
We’re going to be covering a couple of use cases on why you might use a hybrid cloud architecture instead of a private or public cloud. We’re also going to talk a little bit more about how SoftNAS works with the AWS architecture. We’ll then go in and give you a step-by-step guide on how to build an AWS hybrid cloud with AWS, SoftNAS Cloud NAS, and whatever existing equipment that you might have.
Best practices for building an AWS hybrid cloud solution
We’ll cover some best practices for building an AWS hybrid cloud solution, and we’ll also talk more about how to backup, protect and secure your data on AWS.
See the slides: How to Build an AWS Hybrid Cloud
In this article, we’ll cover:
AWS Hybrid Cloud Architecture:
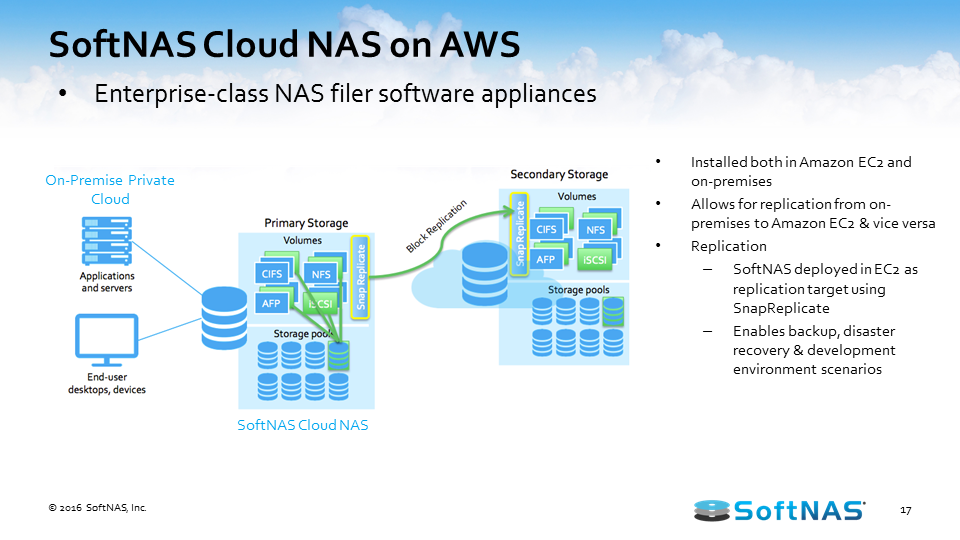
Learn how SoftNAS can be installed both in Amazon EC2 and on-premises
How To Build an AWS Hybrid Cloud:
Watch us create a hybrid cloud using existing equipment, AWS, and SoftNAS Cloud NAS
Best Practices for Building an AWS Hybrid Cloud:
Tips and tricks from the SoftNAS team on how to get your hybrid cloud up and running in 30 minutes.
Buurst SoftNAS is a hybrid cloud data integration product, combining a software-defined, enterprise-class NAS virtual storage appliance, backups, and data movement; and data integration/replication for IT to manage and control data centrally. Customers save time and money while increasing efficiency.
How to Build A Hybrid Cloud with AWS

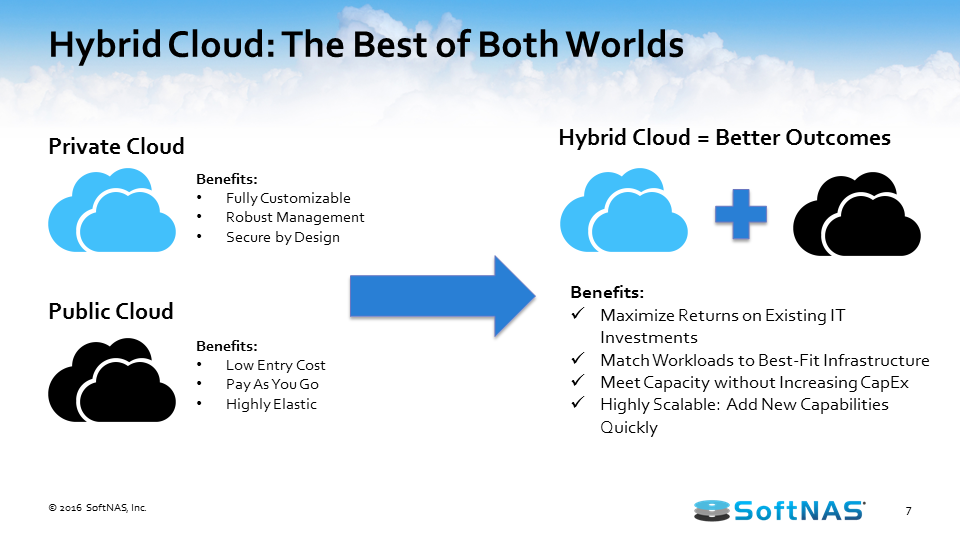
Why build a hybrid cloud architecture with AWS? This boils down to several things. A lot of people are excited about the opportunity to leverage cloud technologies, but they’ve already got a lot of investment made with on-premises equipment. To get the best of both worlds, let’s manage both on-premises and the cloud to create a best-in-class solution that can satisfy our business needs and the use cases that present themselves to us.

Since we are talking about how to build an AWS hybrid cloud, AWS has brought a lot of capabilities to assist with this process, from integrated networking to the ability to very easily create a direct connection from your on-premises network to a virtual private cloud (VPC) sitting in AWS to integrated identity.
If we need to federate your existing active directory or other LDAP provider, we can do that. We can manage these objects just as you would on-premises with perhaps vCenter and System Center. We’ve got a lot of options for deployment, and backup, and we’ve got some metered billing inside of the marketplace that makes things very unique as it relates to consuming cloud resources.
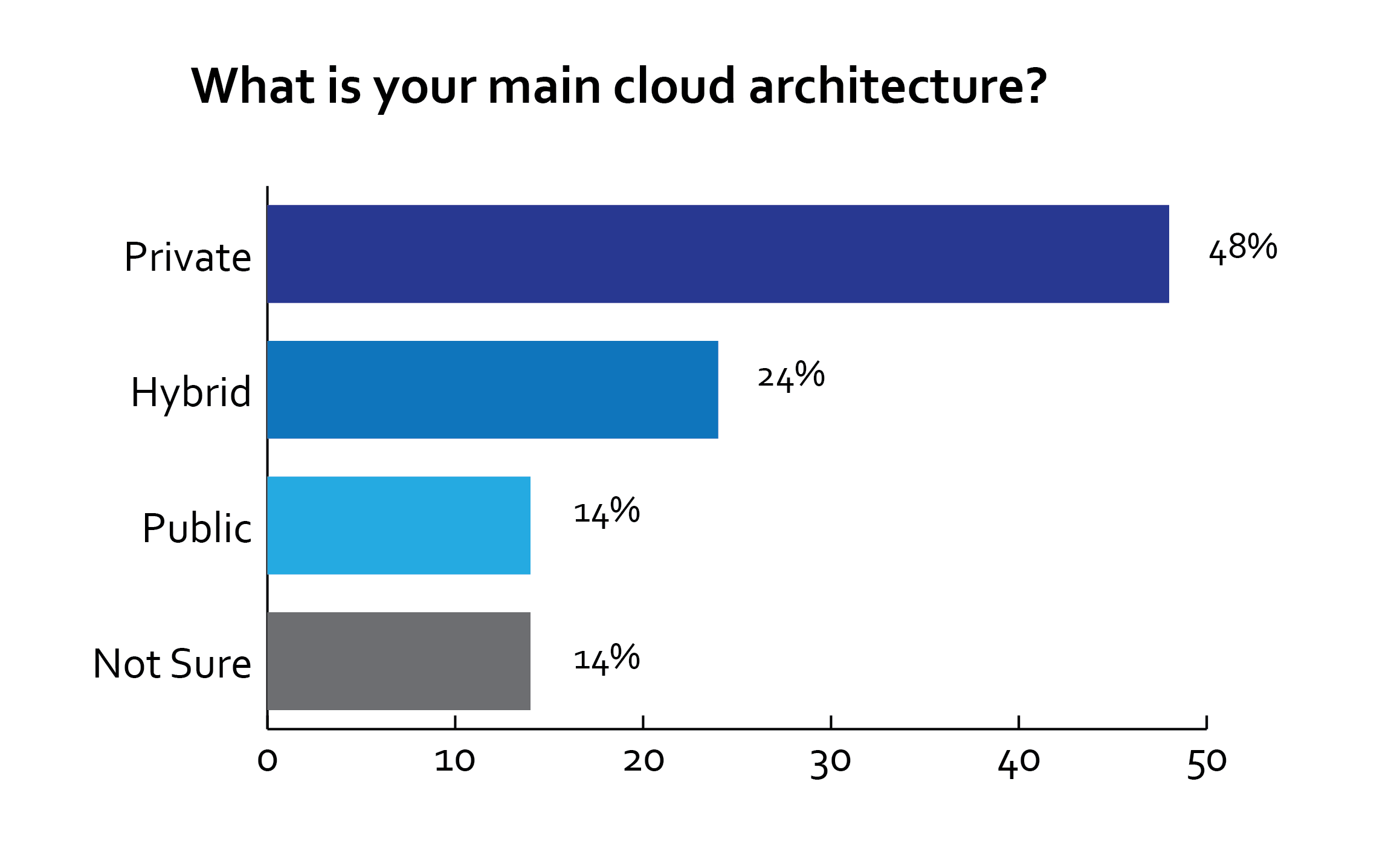
We’re seeing a lot of people interested in the cloud. Yet it appears that a lot of our companies aren’t ready to make that full, all-in commitment. They’re putting their feet in the water, they’re starting to see what kind of workloads they can transfer to the cloud, what kind of storage they can get access to, and what or how it’s really going to play into their use case. 55% is a lot of organizations and, as such, we need a solution that’s going to provide for that scenario and scale with them accordingly, and we think that the best class solution is AWS and SoftNAS.
The chart below shows a survey done by SoftNAS where we asked our customers what their main cloud architecture is:

AWS Hybrid Cloud Use Cases
What are some good use cases for a hybrid AWS cloud? Some common use cases are:
- Elastic scaling
- Backup & Archive
- Legacy application migration
- Dev & Test
Let’s dive into the use cases in more detail. If we talk about elastic scaling, the ability to get access to the resources you need when you need them, be it an increase in access or even a decrease in access, the cloud has many benefits. Traditionally in the absence of elastic scaling, we have to purchase something. We’re purchasing compute or additional storage, but, there’s a time where we’re going to be overprovisioned and there’s probably going to be a time where we’re under-provisioned. So in those peaks and valleys, there’s some inefficiency.
With elastic scaling, we can accommodate our needs, be it seasonal escalations in utilization or be it the retiring of certain applications that require a scale down in usage of compute and storage. So elastic scaling is something that is very beneficial and something we should consider when we talk about leveraging the cloud in any scenario, be it public, private, hybrid, etc.
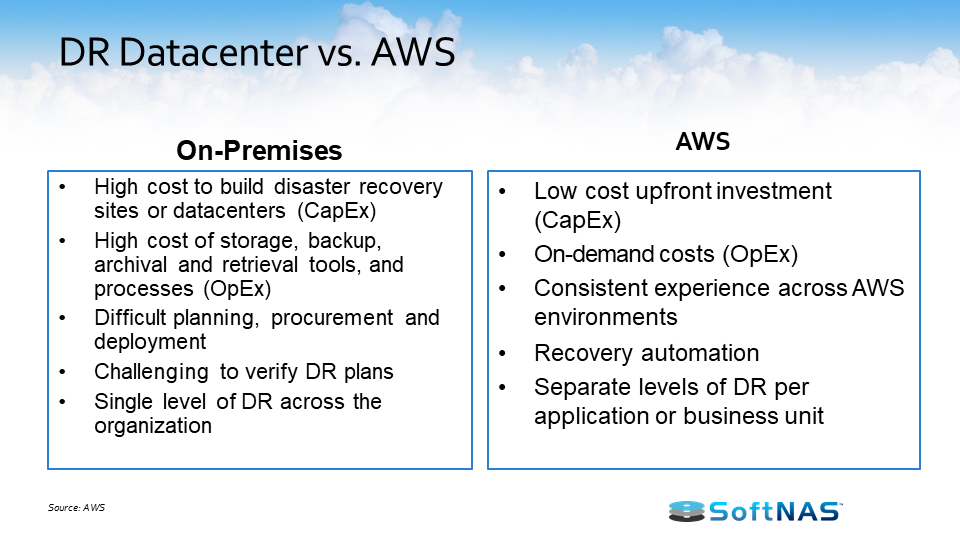
Backup & archiving is a great use case for the hybrid cloud. Traditionally we’re dealing with a lot of very expensive tapes that are sitting out there and we’re routinely struggling with getting our entire data set backed up to this physical media in the windows that we have made available to use before that data actually changes, and then we have to start concerning ourselves about the viability of those tapes when it actually becomes time to restore or gather data from them, and this is just becoming increasingly complex as we add more and more data to it. Are our procedures still adequate? Are our tapes still adequate?
Now we can start leveraging the cloud so we can get real-time backups of data, or very low RPO access to data, replicate data within 60 seconds, replicate it in real-time, etc. So now, rather than having to have a window that is representative of our backup that occurred eight hours ago, we now have access to data, a separate or replicate data set in the cloud that we can get access to whenever and however we need it, be it across regions, across geographies, across data centers, etc.
AWS Hybrid Cloud Best Practices
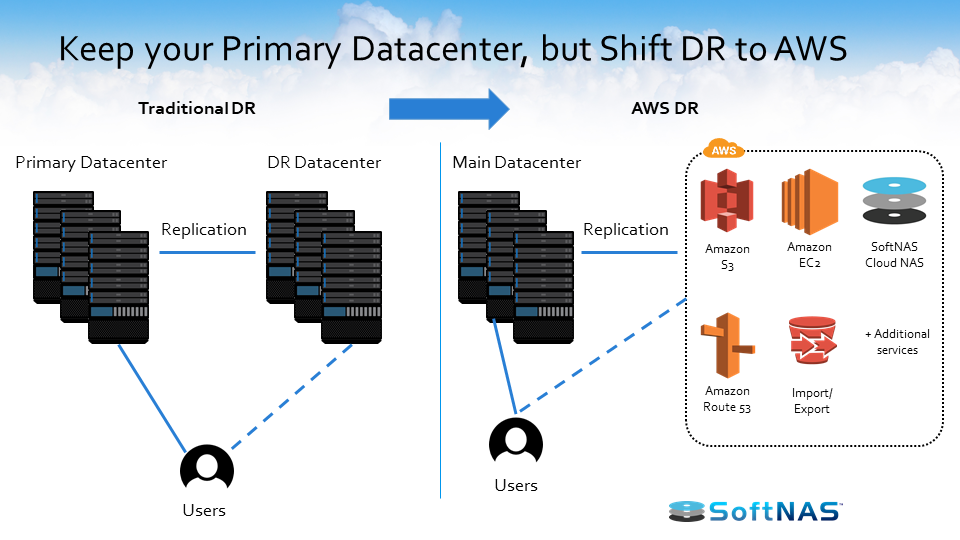
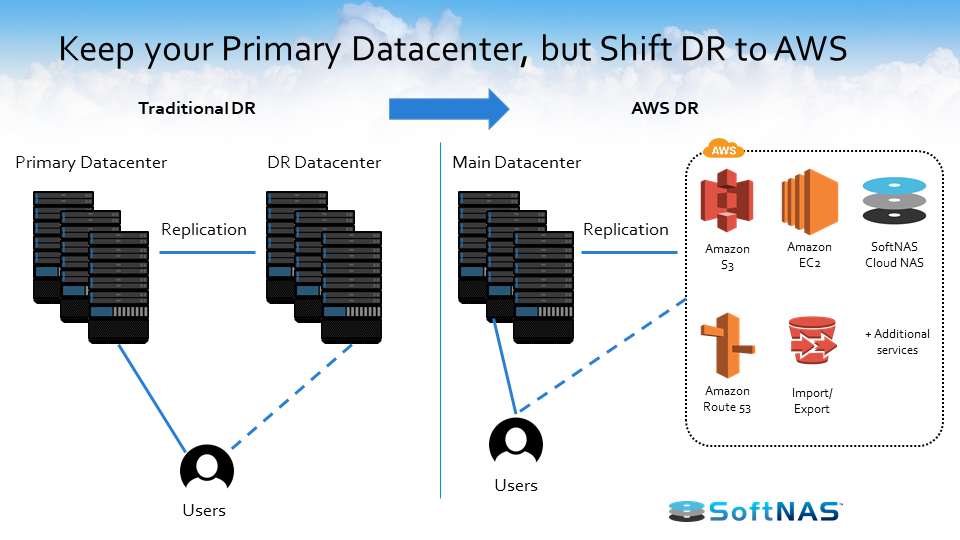
What are the best practices when considering an AWS hybrid cloud architecture? What makes the best use case for an AWS hybrid cloud? Anything I need to look forward to? The first thing we want you to consider is that if you’ve got an application that’s absolutely mission critical and you can’t handle the hiccups that are involved in connecting over that network to the cloud, you might want to consider this for the hybrid cloud.
We can provide local storage and we can back it up or synchronize it to the cloud, but we keep the main storage, the highest performing storage, local, and where it’s needed. But by that same token, if you’re in the environment where seasonally you see a tremendous spike in traffic, those seasonal workloads are prime targets for upload and offload into a cloud infrastructure.
As it relates to cost, if you’re getting ready to consider replacing that five year old SAN or NAS, or making a tremendous investment in compute, it might be worth evaluating what kind of benefit that a hybrid or public scenario is going to bring to the table. As far as security’s concerned, we’ve come a long way with how we can manage security in a cloud environment and in a hybrid environment with the ability to federate our access and authentication environments with the ability to manage policies in the cloud as you would on-premises. We can lock down this information and manage this information almost as granular as you would previously when managing everything on site.
AWS Hybrid Cloud Architecture and SoftNAS Cloud NAS
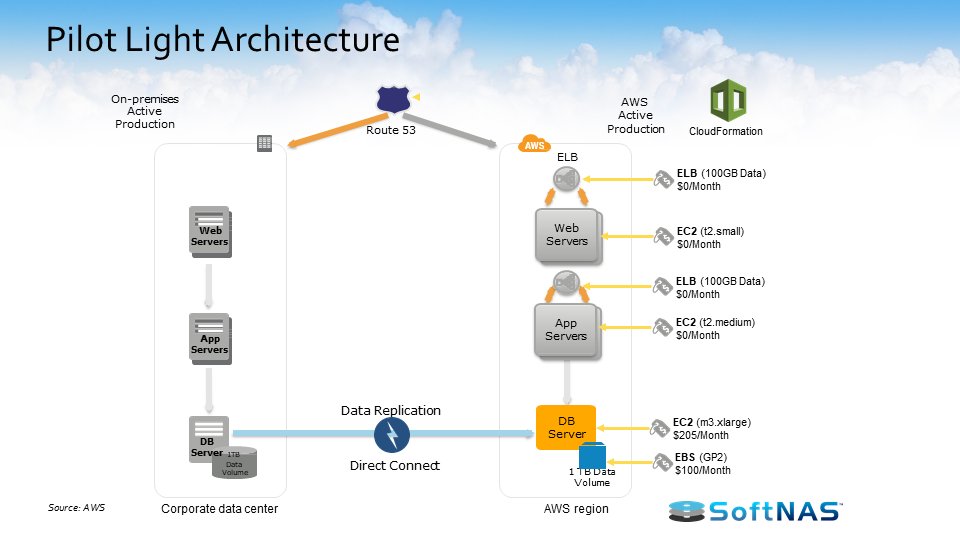
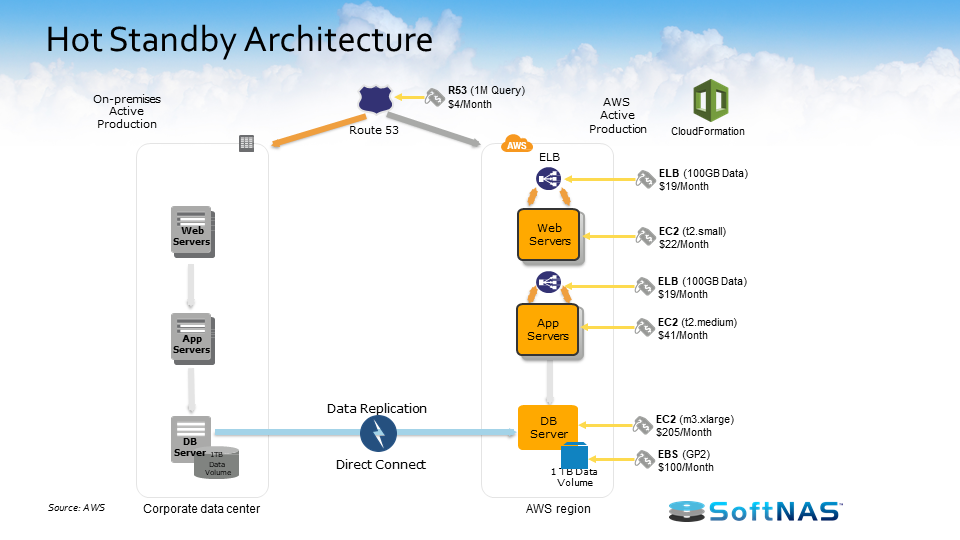
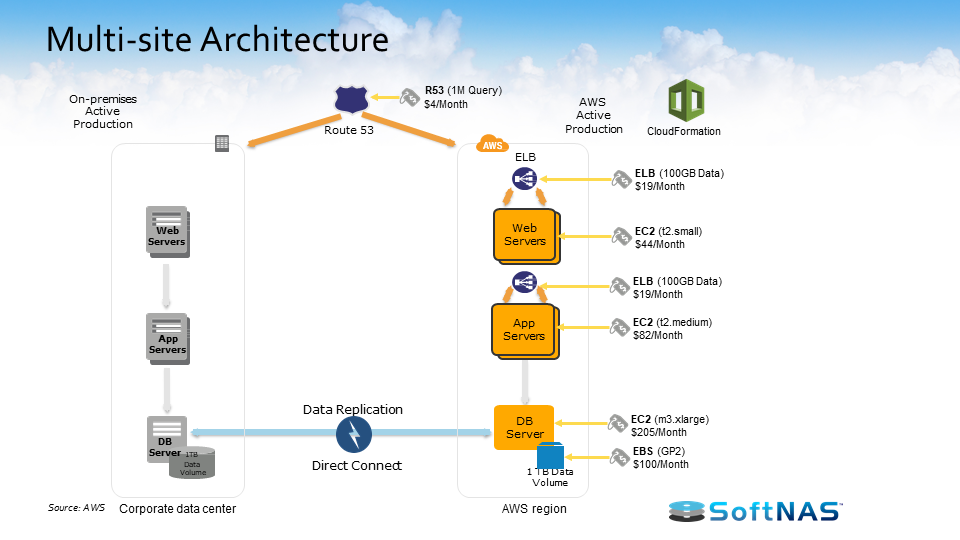
At a high level, we’ve talked about some of the benefits of the AWS hybrid cloud, some of the different use cases, and now we need to start driving in on how SoftNAS Cloud NAS is going to integrate with AWS hybrid cloud architecture and the value we’re going to bring to the scenario. Let’s look at the architecture and features of SoftNAS Cloud NAS and how you can use it to build an AWS hybrid cloud.
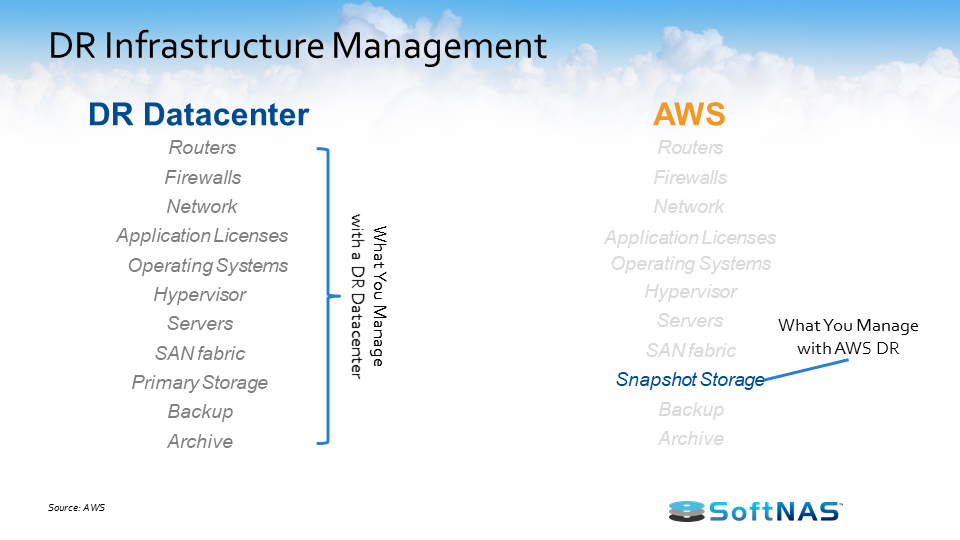
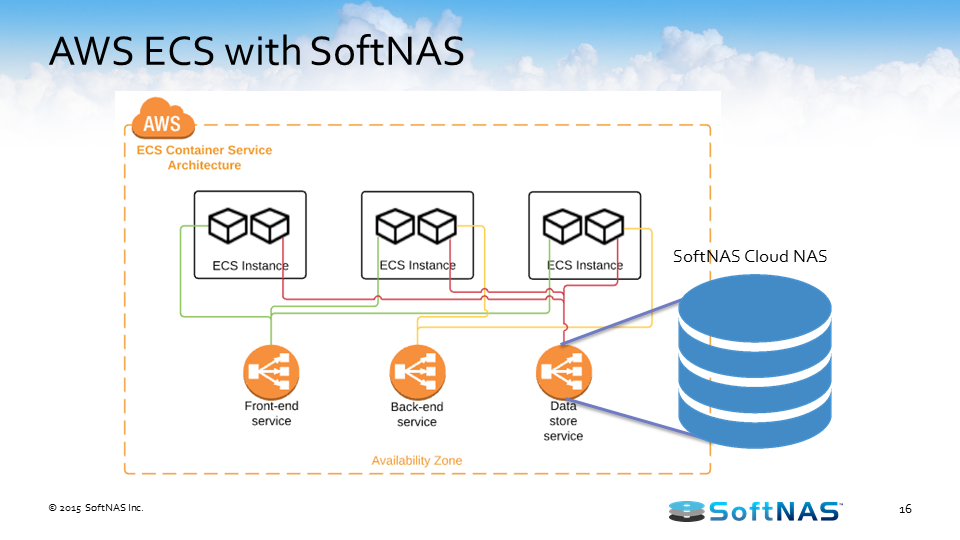
I want to talk about how the AWS hybrid cloud architecture works with SoftNAS Cloud NAS. SoftNAS Cloud NAS, at its base functionality is an enterprise-class Cloud NAS filer. SoftNAS Cloud NAS is going to sit in front of your storage, whether that storage is storage in Amazon S3 object storage, Amazon EBS storage, on-premises storage, it doesn’t matter. But in front of that storage we’re going to provide file system access and block access to those backing disks. So we’re going to give you your CIFS, NFS, AFP, and iSCSI access to all of that storage. And the ability to provision access to your consumers or creators of data, your applications, your servers, your users of data.
With services, they’re used to connecting to, so we’re not going to require you to rewrite those old legacy applications just to leverage an archive data in the S3. We’re going to allow you to connect to that CIFS share, that NFS export, etc.
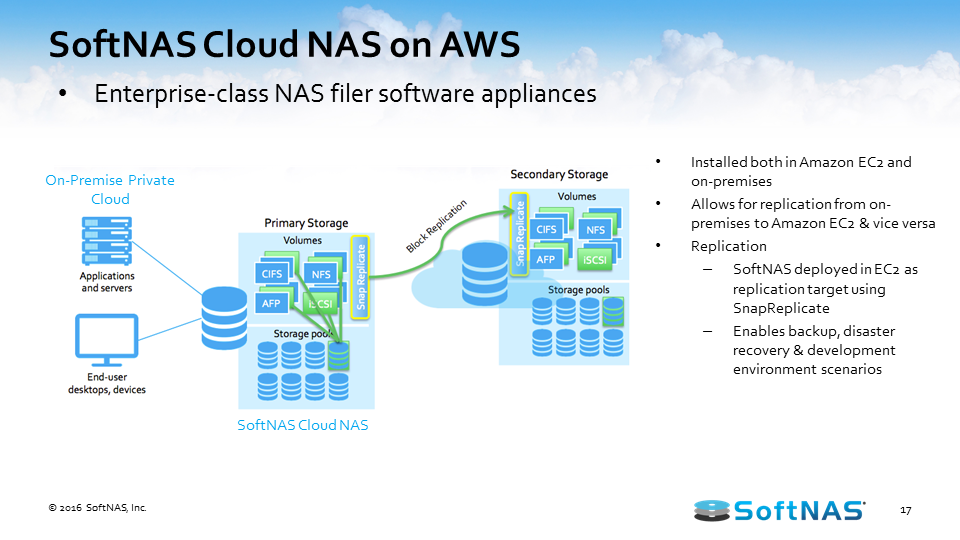
Once we have it set up to provision storage in such a way, we also have the ability to set up a secondary storage environment. Perhaps that secondary storage environment sits in another data center or in a cloud, the AWS cloud here in this instance, and now we have the ability to replicate information between these two environments. We have a feature called SnapReplicate, which we’ll talk about in just a little bit, but essentially we can replicate via an RPO of 60 seconds all our data between those locations however we see fit, however the business case dictates.
Once we have our system set up and we’re leveraging SnapReplicate, we also have the ability to introduce what we call HA or Snap HA – high availability – to this equation. Inside of Amazon AWS or on-premises in the same network, we can set up two systems, two SoftNAS instances, two filers, and we can replicate data in-between those two instances, and we can place them inside an HA protected cluster and in the instance we lose access to that primary, behind the scenes we’ll automatically adjust route tables. We’ll handle the allocations and assignments of VNIs and we’ll automatically allow our end users to create and consume data from that backup set, all the while being seamless and transparent to the end user.
Does SoftNAS work with Veeam for offsite replication? Yes. We have several white papers on what we can do and how we can work with Veeam explicitly, but at a high level we’re able to provide access via an iSCSI LUN or even a share to any of the backup servers, so they can write data to a specific repository that could be cloud-backed, whether it’s EBS, S3, etc., and then we can even leverage some of the advanced features beyond that scenario that are built inside of Amazon to archive that data that’s sitting in S3 based on aging all the way to Glacier, so we definitely work with Veeam and we definitely can work with other backup solutions, and we’ve got some pretty compelling stories there that we’d like to talk with you in more detail about.
How to Build an AWS Hybrid Cloud with SoftNAS Cloud NAS
What I’d like to get into now is actually showing you how to build an AWS hybrid cloud using SoftNAS AWS NAS. What you’re looking at now is what we call our SoftNAS Storage Center. Whether you’re on-premises, whether you’re sitting in the cloud, you’ve either gotten an OVA that you’re standing up via VMware vCenter, or you’re using an AMI that’s published through the AWS Marketplace. The net result is the same; you’ve got a CentOS based operating system that’s hosting the SoftNAS Cloud NAS solution, and the way SoftNAS Cloud NAS works is once we’ve gone through the initial setup, what we’re going to do is we’re going to provision disk devices to this system.
Now, these disk devices could be physical disks attached to the local VMware instance. They could be on-premises object storage that we’re connecting to this instance, etc. They could even be cloud-based objects provided by AWS, and to add these disks we’re going to have you go through a simple wizard. Now, this wizard has many options for allowing you to connect to many different types of storage providers here. The goal is to allow you to connect to and consume those resources you need regardless of what the provider might be. In this particular case, I’m just going to simply choose Amazon Web S3 storage. We could just as easily add local S3 storage as well.
In choosing an S3 disk, we simply step through a very simple wizard. That wizard is going to automatically pull over your AWS access keys and secret access keys based on a role, an IAM role in the background, and then we’re going to define where we’d like this storage to sit. I’m simply going to select Northern California, and then I’m going to provide for the allocation: how much disk space do I want to be allocated in this S3 disk I’m defining? I’m going to define this as 10GB and then I’m going to either enable disk encryption as provided by Amazon or I’m not.
Once we create this disk or these disks depending on how we’re allocating storage provisioning, we’re then going to have to take these disks and turn them into something that SoftNAS can manage, and we do that by attaching these disks to what we call a pool. I’m creating several disks here so we have the ability to go in and manage things across multiple disks, but once we get beyond this disk devices and the allocations of those disks, to get into the pool section of things we go to a storage pool outlet within our console.
Now, storage pools are how SoftNAS manages all of our storage. To create one of these pools, we go through a simple wizard that should look relatively similar to the last wizard. We’re trying to keep things very similar and very comfortable with regards to the UI, and we’re trying to abstract you from the heavy lifting that’s going on in the background. Now, as far as the pool’s concerned, we are going to give it a name. I could call this S3 data just so I know that this pool’s going to be made up of our S3 disk and this is where I’m going to have everything ultimately residing. Now, once we’re giving it a pool name, we do have the ability to introduce different levels of RAID. In my situation, if we’re using S3 disks, we’ve already got an incredible level of redundancy, so I’m just simply going to choose RAID 0 to get some increase in performance striping across all those disks that we’re using in this pool.
Once we’ve defined our RAID level, we select the disk we’d like to participate or assign to this pool, and then we have the option to enable encryption at the SoftNAS pool level. So disk encryption is provided by the hosting provider. LUKS encryption is provided by SoftNAS in this case. Once we’re happy with those selections, we can go ahead and create this pool. Once the pool’s defined, we can then create access points or particular volumes and LUNs that our consumers or creators of data can connect to, to either read or write data to that S3 back in, in this case.
So we’ve got a storage pool called S3 data. We then go to our volumes and LUNs tab to create those shares that our users are going to use to connect to. In this particular instance, maybe we want to store all of our Windows users’ home drives on this S3 pool, and we’re going to create a volume name. Volume name’s important because that’s going to be the root name of your export and the root name of your CIFS share, so we want it to be something that fits within the naming parameters of your organization. We then assign it to one of those storage pools. S3 data’s the only one we happen to have right now, but once we have that created, we’re going to choose the file system we’d like to apply to this share.
By default, we automatically check an export by NFS. We also have CIFS for our Windows users and we even have the Apple filing protocol if you’re a Mac shop and you need that. We also can define an iSCSI LUN connecting to this volume. Now, anytime we provide an iSCSI LUN, we will have to go in and we will have to grab a LUN target. Now, that target is provided by the system automatically for us but once we grab that we then can go ahead and continue on this process, ultimately having an iSCSI target, a LUN target that people can connect to and consume this information as it was in the other disk on their system. So for this exercise, I’ll simply leave it in NFS and I’ll choose CIFS.
The next option we have is dealing with the provisioning of this volume. Thin provisioning says anybody who connects to home drives and writes data to it, home drives are going to scale its capacity up to the maximum capacity of this pool, 17.9GB in this case. Thick provisioning says I’m going to limit you to a subset of that available size, 5GB, 10, whatever that might be. Also, at the pool level, we can enable compression and deduplication, so if your data is such that it can benefit from either one of these, we can architect accordingly and leverage both or either one of those as it relates to this particular volume.
The second thing that’s interesting about how SoftNAS manages volumes is that we’re going to give you the ability by default to manage snapshots at the volume level, and snapshots are a great thing. It is your data at that point in time, and the great thing about how SoftNAS manages this is that at any point in time, we can go back into a snapshots tab that I’ll show you very shortly and pull data out from that point in time and mount as another readable and writable volume completely independent of your production data. So we can define those schedules for snapshots here, and then once we’re happy we can go ahead and create those shares.
Now at this point, if this controller is sitting onsite, you’re free to go ahead and allow users to connect to those CIFS shares, connect to the NFS export, or mount that iSCSI LUN. We also can leverage or integrate or use Kerberos and LDAP for access. We also can integrate with an active directory, so I don’t have an active directory here to integrate with directly but we do step you through a very simple wizard that simply takes the name of your active directory, the name of your domain controller, and appropriate credentials, and we’re going to do all the heavy lifting behind the scenes, join your active directory, synchronize users in groups and you can continue accessing and (cuts out) your data as you always have within a Windows network.
Once our volume’s out there and we’ve got data written to that storage pool, I mentioned that we created a snapshot routine when we built that volume, so we have the snapshots tab. Now, there’s nothing currently in this tab because we just created it, but ultimately what would happen is we would take snapshots and the snapshots would start to populate in this list. I’m just simply creating snapshots or forcing snapshots so you can see this process that we’re going to perform. But the point is here if at any point in time someone comes to you or there’s a business case that requires you to provide access to data at a prior point in time, you simply choose that point in time from this list and we can create what we’re calling a SnapClone from the snapshot, and a SnapClone is a readable, writable volume that contains that data set from that point in time.
It’s automatically created and put up inside your volumes tab so now you can provide that application, that business unit, and that customer access to that data so they can get what they need, and recover what they need, without adversely impacting your production data set. So something very simple to do potentially could even be automated via at-REST APIs, but very, very powerful.
Now that we have the concept of snapshotting and the ability to go back to a point in time, we can start extending upon the functionality of this SoftNAS implementation. So we’ve talked about filer access, the ability to give that backend storage regardless of storage type CIFS, NFS, iSCSI, and AFP access. We’ve talked about snapshotting that data at the volume level. Well, now we can start talking about snapshotting and replicating this data at the entire SoftNAS instance level, and we call that SnapReplicate. And the way SnapReplicate works, and I’m going to share a different browser at this point where both of these things are open. So hopefully everybody’s seeing this; what you’re seeing now is the same storage center app that I just showed you except you’re seeing another instance.
So the notion is, here I have one instance of SoftNAS on-premises or in the cloud and I have another instance of SoftNAS either on-premises or in the cloud, the whole hybrid solution. And if I go to my ‘Volumes and LUNs’ tab here and I refresh this, we should be able to see those volumes that we created, that home drives that are sitting on top of S3 data in that SnapClone. Well, if we start talking about replicating this entire data set, what we’re going to do is we’re going to go into this SnapReplicate Snap HA applet that we have here, and we’re then going to create a second SoftNAS machine. I call it ‘target’ in this case.
To get this target machine ready to accept that replicate data set, the first thing we need to do is we need to make sure we have enough storage provision to this device to accommodate the storage pools. So if I look at my storage pool on this machine that we just built, S3 data, I only have 17.9GB. I’ve got 40GB provisioned on my target machine. I think we have enough disk space. Now, the disk space doesn’t have to be identical. We could have a local high-speed disk, direct-attached SSD on the source on-premises, and this target might be in the cloud completely backed by an S3 disk.
We need capacity here, so once we have the capacity the second thing we need to do is we need to create the storage pool that we want to replicate. So here we need to create an S3 data storage pool, so once we create that storage pool, we select the RAID level, we assign the disk we’d like to write to this, and then we hit ‘create’. So once this pool is created, we’re completely set up and we’re ready for this target machine to accept replication from this source machine. We’re ready to accept replication from our on-premises VMware infrastructure to our AWS cloud infrastructure, and we do this by opening up again that SnapReplicate app that I was talking about.
I’m going to open that up on both sides, and what we’re going to do here is we’re going to start this process by adding replication. Now, when we add replication what we’re doing is we’re taking some simple information from you and we’re doing a lot of things behind the scenes, so as far as the simple information from you is concerned, I need to know the hostname or the IP address of that target machine. In this case, it’s 10.23.101.8. And the next thing I need is permission to modify that target machine, specifically the SoftNAS storage center.
We do have a user to that I’m going to provide access. Once we provide that access, we’ll go ahead and set everything up behind the scenes, we’ll build that replication pair, and then ultimately what’s going to happen is we’ll send information about how SoftNAS is configured from the primary machine over to the target. We’ll build the volumes and LUNs just like they’re built on your primary machine to the target, and then we’ll start replicating the data from those volumes and LUNs across to that target pair.
Now, some of this takes a little while, so you might see a fail happen just because we rushed things and you’ve got some latency involved here, but we’ll continue that process until that actual first mirroring is complete. Once the mirror is complete, we’ve got an RPO of 60 seconds. Every minute, we’re going to send another snapshot to that target machine that represents all the data that is changed. So now you have all of your data being replicated from on-premises to AWS as one scenario.
Several different use cases for this; you could this as a means to migrate data or ingest data into the cloud for ultimate migration to the cloud. You could use this as a backup solution. You could even use this as a DR node. Now, as it relates to business continuity and disaster recovery since we do have a data set sitting somewhere else, we could ultimately go in if this primary server becomes unavailable for whatever reason and point everybody to this secondary node, which pretty much elevates the secondary node to primary status and have everybody connect with that. That’s a manual process, you know, we’d have some networking to deal with on the back end, but not too bad, something we could write a procedure around.
But it would be great if we could automate failover. Now, to that end, we have a feature called Snap HA. Snap HA does have a requirement that these two nodes sit in the same network. So if you’re connecting from on-prem to AWS, we’d have to have that direct connection so the network’s the same between these two nodes, that BPN connection. If you’re in AWS, they’re going to sit within the same BTC separated by subnets, etc.
To get SnapReplication to work, we’re again going to go through a very simple wizard. We’re going to click on this ‘Add Snap HA’ button and we’re going to ask you for more information the first thing we’re going to need is how we’re going to allow our users to connect to this data set. If you think about this conceptually, we’re going to put a virtual IP above this source in this target node and all of our users are going to connect to that virtual IP anytime they need storage. They’re going to mount via that virtual IP or the DNS pointing to that, and route tables are going to behind the scenes take care of who they’re getting their storage from, whether it’s the source node or the primary node.
Now, I’m going to just randomly provide a virtual IP here since I’m completely private, and what’s going to happen is it’s going to take my AWS access key and secret key so it can start modifying route tables in the AWS cloud specifically belonging to that VPC we’re a member of, and then it’s going to install this HA feature. So there’s quite a bit going on in the background right now, but the notion is when we’re doing we’re going to have a SnapReplicated pair that is now highly available. All of our users are going to connect to and consume their storage through that virtual IP to that too in this scenario. Our graphics on both of these nodes will change to illustrate that, and if a primary node becomes unavailable for whatever reasons, we will monitor the health and status of that primary node and we will automatically failover to the target node if we need to.
So very quickly upon noticing the service is no longer available on that source node, we’ll modify route tables. We’ll adjust the assignment of VNIs if required, depending upon how we’re connecting to the storage, and we’ll elevate the target to primary status. We’ll break the high availability pair so we have time to go back and remedy whatever problem was causing that source node to become unavailable in the first place, and then our users are none the wiser. If your CIFS user’s connecting to your files, you still see your files. If you happen to lose access and we’re going into a failover, you might see the little spinning icon for a couple of seconds longer than normal, but you’re ultimately going to get access to your data, and again that data’s subject to a 60 second RPO. So as you can see, my graphics have changed to let you know that both machines are currently set up; one is a primary, and one is a secondary. We’re connecting through and consuming through that private adapter, and at this point, this is where we could illustrate a failover process if we needed to.
It’s a lot of information that we’re covering at a high level so again I implore you to reach out should you need any additional information or more detail on any of these functions that we covered, or, you know, you see some things in the background that we haven’t covered. Let us know and we’d love to have these conversations, but in carrying on from the demo what I’d like to do is I’d like to go ahead and switch back to a PowerPoint, and we could take this time to go ahead and address some questions.
I see one question here, I see capacity; does this also show performance info? So it’s just performance info to a certain degree, and the reason I say to a certain degree is, and I’ll show you this by sharing out my desktop, is that we do have a dashboard up here. That’s going to give you certain metrics about the health and status of your environment. So once that loads, you can see here we’ve got percent of CPU, the megabytes per second and IO and the cash performance. If you need actual performance of the volume itself, then, you know, we can run tests outside of SoftNAS and we can help you configure those tests or what tools to use for those tests, etc., and hopefully that addressed that. If it didn’t, let us know and we can definitely go into that in more detail.
And let’s not forget that we’ve got a lot of use cases that are sometimes forgotten, the test, the dev, the QA and the production. When leveraging SoftNAS Cloud NAS with AWS, we’ve now got a very easy way to potentially replicate our data from a point in time into the test dev and QA environments, keeping them up to date in a very quick and efficient manner, and that is something that’s very important for organizations, something that again we’d love to talk to you about.
So this is just the tip of the iceberg. Definitely we want to continue this conversation, but we’re going to start driving down more into some of the features and extended options of SoftNAS that we didn’t necessarily cover in great deal in the demo, and we talked about SnapReplicate and I’m talking about it again here because SnapReplicate really is a great solution. It allows us to not only make sure our data is replicated from point A to point B across the availability zone, etc., or across the region, it’s going to make sure that our SoftNAS configuration is replicated as well.
So we would have, in the event of catastrophic loss, we would have that replicate data set. We would also have a storage controller just waiting and happy to service the needs of your consumers or creators of data, your applications, your servers, your users, etc. SnapReplicate doesn’t have the same requirements as SNAP HA meaning all it needs is network access. We don’t have to exist on the same network, so we do operate across the region. We will operate between data centers so you can get a replicate set based on your particular scenario, your particular requirements.
And as far as the data protection is concerned, you know, we’re going to leverage a lot of features that AWS provides, you know, virtual private cloud. We’ll completely isolate the SoftNAS controllers if we need to. We can control access to our virtual private cloud via the security groups and the IAM policies that AWS provides. We have data encryption provided by AWS at the disk level. And beyond that or standing on top of that data encryption, we have the ability to start doing things at the SoftNAS level.
As far as encryption is concerned, we can encrypt at the pool level using LUKS encryption. Depending upon which versions of SMB and NFS we use, we can leverage in-flight encryption. We can use SSL to encrypt access to our admin console. We can tunnel through SSH. We can do a lot of things to protect this data as it rests in place, as it goes in flight, and to protect the data as it relates to multiple data sets, SnapReplication, snapshotting, etc.
So just to give you again a high level overview of this product, SoftNAS, that enterprise cloud NAS filer is our default functionality and everything we’ve talked about thus far can be done through the GUI, extracted from the heavy lifting behind the scenes. The notion is you’re going to have a business case and we want you to be able to configure that storage based on that business case without necessarily having a degree in storage that lets you or requires you to understand the bits and bytes of every piece of the equation.
We do have a REST API and a CLI if there’s ever any need to develop against that or automate that. We do have some different options available to you. We do support cross-data center replication and cross-zone PPC replication. We have a file gateway. Our admin UI is based on HTML5. We are CentOS and our file system is based on top of ZFS. As far as integration is concerned, naturally, we’re talking about AWS but we’re not limited to AWS by any means. We support AWS, Microsoft Azure, CenturyLink Cloud, and several different providers of onsite storage, and we have a lot of technology partners that we’ll briefly highlight on the next slide that bring different means of accessing and provisioning storage to us when talking about different on-site solutions.
We do also offer, you know, as a file system again, NFS, CIFS, your traditional file systems that you see everywhere, but we also offer AFP for those cases where you do have a Macintosh native network as well as iSCSI, and as far as our data services are concerned, compression, inline deduplication, snapshotting. We do have multi-level caching. We can implement read caching and write logging for increased performance of your storage.
We do manage everything via a storage pool. We offer thin provisioning so things can dynamically grow. The writable SnapClones, just to revisit them quickly, very important feature, very effective feature, getting access to data or providing access to data at a prior point in time, something that, you know, is not always the easiest to do. SnapClones are readable and writable and completely independent of your production data as we need them to be. And again, we’ve also talked about encryption, AES 256 LUKS encryption at rest, and we can also support encryption in flight.
SoftNAS Cloud NAS Overview
So just to talk about the different product offerings, we do have SoftNAS Cloud NAS, the product that we illustrated in the demo. SoftNAS is an enterprise-grade cloud NAS filer. It does support both on-premises implementation and public file implementation (i.e. AWS hybrid cloud) and we also have SoftNAS for Storage Providers for those that want to host the SoftNAS and provide managed services in storage through SoftNAS to their end-users. If you have any questions on either one of these, specifically want to dive into what we offer for service providers, again, definitely reach out and let us know. We’d very much enjoy talking about that.
We also have a fantastic white paper that we co-developed with AWS where you can learn more about how SoftNAS Cloud NAS architecture works in conjunction with AWS hybrid cloud architecture. If you do have more questions, or you have any specific AWS hybrid cloud use cases that you think SoftNAS might be able to help you with, please feel free to contact us.