
Off-site Data Replication and Cloud Disaster Recovery for Amazon EC2
In the cloud world we live in today, it’s important not only to protect corporate data and IT infrastructure from outages and failures, but also meet expected Recovery Time Objectives (RTO) and service levels established by the business for its critical applications. In the event of logical or physical failures, it must be possible to recover and restore service levels quickly with no loss of data. In the event of a catastrophic disaster that takes down primary IT infrastructure, the ability to bring the business back online in a reasonable time frame is paramount – to business continuity and IT management careers.
When we manage our own data centers, we have more control over what happens, enabling IT and management to better contain and mitigate risks. When we outsource IT infrastructure or move IT systems and data into data centers controlled by others, there is a real loss of control – we are beholding to the cloud providers. However convenient it may be to have a vendor to blame for an outage, ultimately management is responsible for restoring business operations and service levels.
So how can we reap the many benefits of moving business-critical applications, data, and IT infrastructure into the cloud, into third-party data centers and managed service providers, yet retain enough control to recover safely from even the worst possible failure and disaster scenarios?
In a word – replication. By replicating our data from a primary data center to another location, we have the ability at any point to switch over to a secondary data center to continue operations, even in the face of the most devastating disasters. If replication is such an obvious solution, why don’t more businesses take advantage of it? Historically, it has been too costly to duplicate the IT infrastructure required.
Fortunately, the very on-demand nature of cloud computing infrastructure lends itself well to implementing cost-effective off-site disaster recovery.
It all starts with replication of the most critical part of IT infrastructure – corporate data and IT data. Corporate data includes all the databases, office files, file servers and other business data. IT data includes the “meta data” and systems required to quickly reconfigure and recover infrastructure after a failure has taken place.
The following diagram shows, for example, how off-site data replication and cloud disaster recovery can be configured using Amazon EC2. SoftNAS SnapReplicate(tm) provides the solution.
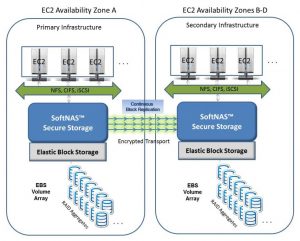
We see two sites in the above diagram – a set of Primary Infrastructure running in one Amazon EC2 availability zone (AZ), and Secondary Infrastructure in a different availability zone (or regional data center). The Amazon EC2 virtual machine workloads, or instances as they are called, connect to shared storage managed by SoftNAS.
SoftNAS provides the bridge between EC2 computing and commercial-grade Elastic Block Storage (EBS), with advanced NAS features like scheduled snapshots, compression, error detection and recovery, RAID array protection, and more.
The Primary and Secondary data centers are connected via “continuous block replication”. As data is written by the primary systems, the data changes are packaged up and transmitted securely over the network from the Primary to the Secondary on a continuous basis. Continuous replication keeps the Secondary site “hot” – ready for use at all times.
In the event of a simple failure, such as a failed EBS volume, the RAID array compensates and no downtime impacts occur. However, should an entire Amazon availability zone go down (e.g., a major network switch or router fails, critical power failure, server failure, etc.), computing instances and their data unexpectedly and instantly become unavailable for the duration of the outage.
With the above configuration, it’s a matter of making a few DNS changes and failing over to the Secondary system, bringing up the required computing instances on the Secondary and restoring normal service levels – which can be accomplished in 30 minutes or less.
With SnapReplicate, the IT administrator simply issues a “Takeover” command on the Secondary node, updates DNS entries and starts up the workload instances (web servers, database servers, application servers, etc.). Within a matter of minutes, DNS updates get replicated throughout the Internet and service levels return to normal. mitigating the outage.
Continuous Protection
SnapReplicate provides continuous protection, 24 x 7 x 365, ensuring there’s always an identical Secondary environment with up-to-the-minute data from the Primary, right up to the point of a failure event. The Secondary now takes on the role as the new Primary.
Later, when the failed cloud services are restored, the Primary running in availability zone B/C/D is connected back to the new Secondary node in zone A. Once an initial re-sync replication cycle is completed, the two sites are now synchronized again. Normal operations can simply continue in this new configuration, or during a scheduled maintenance window, a “Giveback” command can be issued to “fail back” control to AZ A, which becomes the Primary once again.
The beauty of the SnapReplicate cloud DR solution is that it solves both the full-scale site redundancy problem, and it does so at a fraction of the normal cost. On the Secondary site, only the SnapReplicate target is required to be operational – all other computing instances can be stopped, so that no hourly charges are incurred until the Secondary site is actually required fully online.
Better Than Clustered Filesystems
Unlike clustered filesystems, like GlusterFS and others, SnapReplicate is much more cost-effective, performs better and costs less to operate – and there’s no risk of the “split-brain” data corruption problems that occur with clustered filesystems, where nodes can get out of sync with each other, resulting in data corruption, application and website failures.
Clustered filesystems must compare files and folders across all nodes to detect and synchronize any data changes. This works okay in smaller lab implementations, but in real-world practice, you typically have tens of thousands to hundreds of thousands of files. The enormous number of files causes clustered filesystem replication to get caught up in an endless replication cycle – sort of like painting the Golden Gate bridge – by the time you can finish, it’s time to start all over again.
Clustered filesystems are also slower, penalizing every write operation by making each write wait for completion and confirmation by all nodes.
The end result is, clustered filesystems result in much greater bandwidth consumption across the sites, with correspondingly higher bandwidth costs to operate the system on a 24 x 7 basis. Worse yet, as the number of nodes increase, so do these costs and performance impacts.
On the other hand, SoftNAS uses ZFS – a proven, reliable high-performance copy-on-write filesystem – which only stores data changes once. And within one minute or less, SnapReplicate ensures all data changes are replicated from the Primary to the Secondary node. And since only the actual changed data blocks are sent over the wire, there is no need for repetitive, wasteful file comparisons at any time.
More Useful than Cloud Backups for Rapid Disaster Recovery
Off-site backups are good – you should have a good backup strategy; however, in practice, when a failure event occurs, you don’t have time to:
1) configure and develop IT infrastructure at a temporary site,
2) roll a restore of the backup (and hope it works),
3) configure everything and get it back up and running, while under the immense pressure associated with a major outage.
Just restoring one terabyte of data over the Internet could take up to a day! (at an effective throughput over the Internet of only 68 Mb/sec at an average 30 milliseconds of latency). Cloud backups are useful as a worst-case-scenario recovery mechanism, to save the company in the unlikely event that both Primary and Secondary sites are permanently destroyed and unrecoverable (unlikely, but it always pays to have a backup).
With SnapReplicate, the data on the Secondary site is always current, ready to go and immediately available whenever it’s required to bring the business back online. Storage is relatively cheap, having a duplicate copy is well worth it when the chips are down.
Saves Time, Money, and Resource
Historically, DR solutions have required duplicate live environments at multiple data centers, which means corresponding costs for equipment, software, and hardware, and IT resources at each site.
With cloud DR using SoftNAS, no hardware is required – at either site.
Amazon EC2 provides on-demand storage and compute capacity as it’s required. SnapReplicate keeps the Secondary site hot with all up-to-the-minute data changes using block replication, which only sends over the actual data changes as they occur in real-time.
How Long Does It Take to Configure SnapReplicate?
SnapReplicate is the fastest, easiest way to configure replication between two sites of any NAS available (even the most expensive NAS by the big brand vendors). How can we prove that claim? Just watch this 6-minute video, and you will see how to configure SnapReplicate between a Primary and Secondary site in less than 5 minutes (including the time required to explain it).
About SnapReplicate
SnapReplicate is a feature of SoftNAS Professional Edition, the most cost-effective and only commercial-grade NAS solution available for DR across Amazon EC2 availability zones and multiple data center regions worldwide.
Check Also
Cloud Disaster Recovery
Using AWS Disaster Recovery to Close Your DR Datacenter




