Maintaining physical Disaster Recovery (DR) data centers grows more cost-prohibitive yearly. Moving your DR data center to the Amazon Web Services (AWS) Cloud enables faster disaster recovery and more excellent resiliency without the cost of a second physical data center. In this article, we’ll discuss how to use AWS to manage disaster recovery in the cloud.
Use AWS to manage disaster recovery in the cloud.
How to use AWS Disaster Recovery to Close Your DR Datacenter?
We’ll give a brief overview of:
How AWS disaster recovery works,
The benefits of using AWS DR,
An overview of DR architectures
AWS disaster recovery example
AWS Disaster Recovery Overview
Before we begin, there are four terms you should be familiar with when discussing disaster recovery:
Business Continuity:
Ensuring that your organization’s mission-critical business functions continue to operate or they recover pretty quickly from a serious incidence.
Disaster Recovery:
Disaster recovery is all about preparing for and recovering from a disaster, so any event that hurts your business; things as hardware failures; software failures; power outages; or physical damages to your building like fire, flooding, hurricanes, or even human error. Disaster recovery is all about planning for those incidents.
Recovery Point Objectives (RPO):
RPO is the acceptable amount of data loss measured in time. If your disaster hits at 12:00 PM and your RPO is one hour, your system should recover all the data that was in the system before 11:00 AM. Your data loss will only span from 11:00 AM to 12:00 PM.
Recovery Time Objective (RTO):
RTO is the time it takes after a disruption to restore your business processes to their agreed-upon service levels. If your disaster occurs at noon and your RTO is eight hours, you should be back up and running by no later than 8:00 PM.
Keep your Primary Datacenter, But Shift Disaster Recovery to AWS
We’re not saying that you need to shut down all of your data centers and migrate them to AWS. You can keep your primary data center, but close your DR data center and migrate those workloads to AWS.
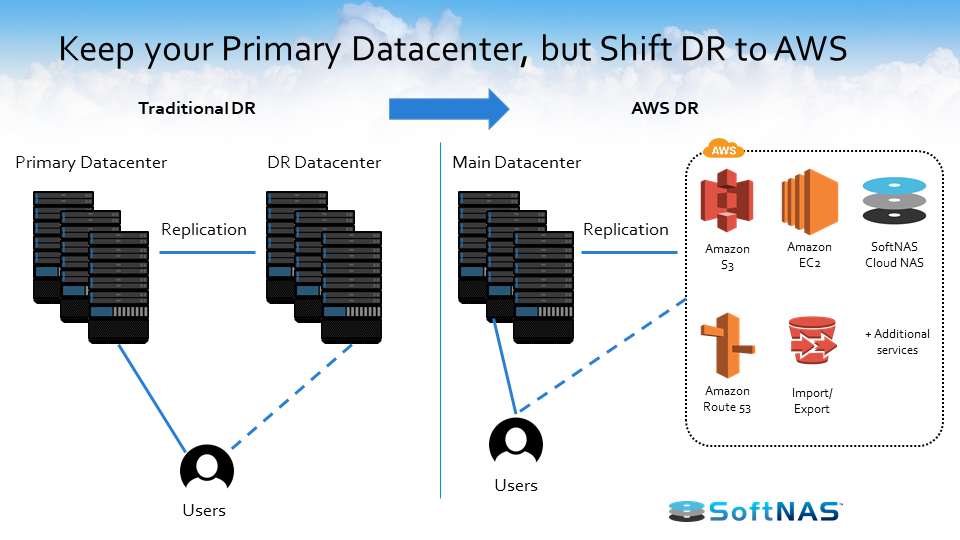
In the image above, we have our traditional DR architecture on the left. You have your primary datacenter, and then you have your DR datacenter. With the DR datacenter, there is replication between the primary and the DR datacenter. You can recover as soon as a disaster happens in the primary datacenter. This way your users are still able to be up and running without too much of an impact.
With traditional DR, you have the infrastructure that’s required to support the duplicate environment. Physical location, power, cooling, security to ensure that the place is protected, procuring storage, and enough server capacity to run all of missing critical services — including user authentication, DNS monitoring, and alerting.
On the right, we have Disaster Recovery managed on AWS. What you see is the main datacenter, but you can set up replication to the AWS Cloud using a couple of services including Amazon S3, Route 53, Amazon EC2, and SoftNAS Cloud NAS.
You’ll get all the benefits of your current DR datacenter but without having to maintain any additional hardware or have to worry about overprovisioning your current datacenter.
Physical Datacenter On-Premise vs AWS
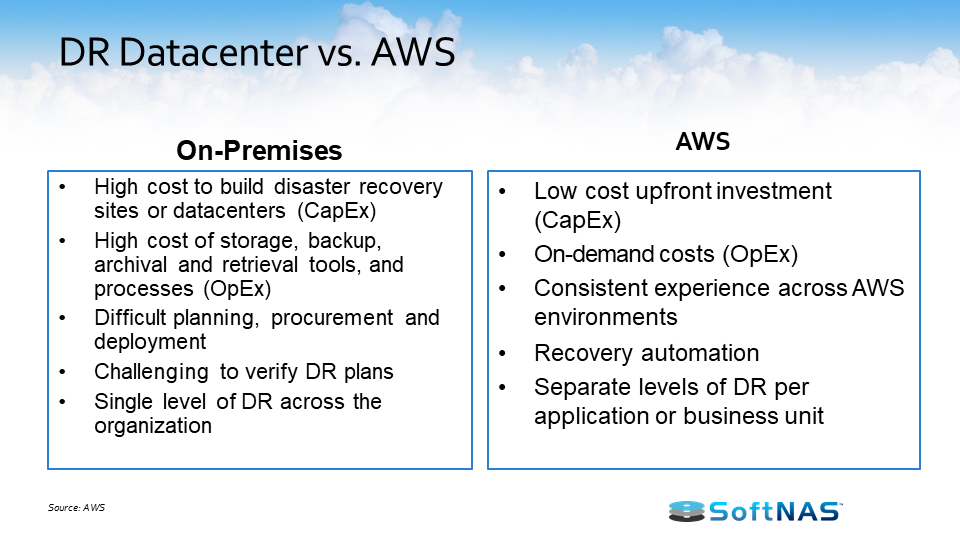
Let’s compare a physical DR data center vs. AWS Disaster Recovery. With your DR data center, there’s a high cost to build and maintain it. You’re responsible for storage, power, networking, the internet, and more. There are a lot of capital expenditures involved in maintaining the DR datacenter.
Storage, backup tools, and retrieval tools are expensive. It often takes weeks to add in more capacity because planning, procurement, and deployment just take time with physical datacenters. It’s also challenging to verify your DR plans. Testing for DR on-site is time-consuming and takes a lot of effort to make sure it’s working correctly.
On the right, we have the benefits of using AWS for DR. There are not a lot of capital expenditures when using AWS. The beauty of using AWS to manage DR is it’s all on-demand so you’re only going to pay for what you use.
There’s also a consistent experience across the AWS environments. AWS is just highly durable and highly available. There’s a lot of protection in making sure that your AWS DR is going to be up and running to go. You can also automate your recovery. Finally, you can even set up disaster recovery per application or business unit. So different business units within an organization can have different recovery objectives and goals.
Managing AWS DR Infrastructure
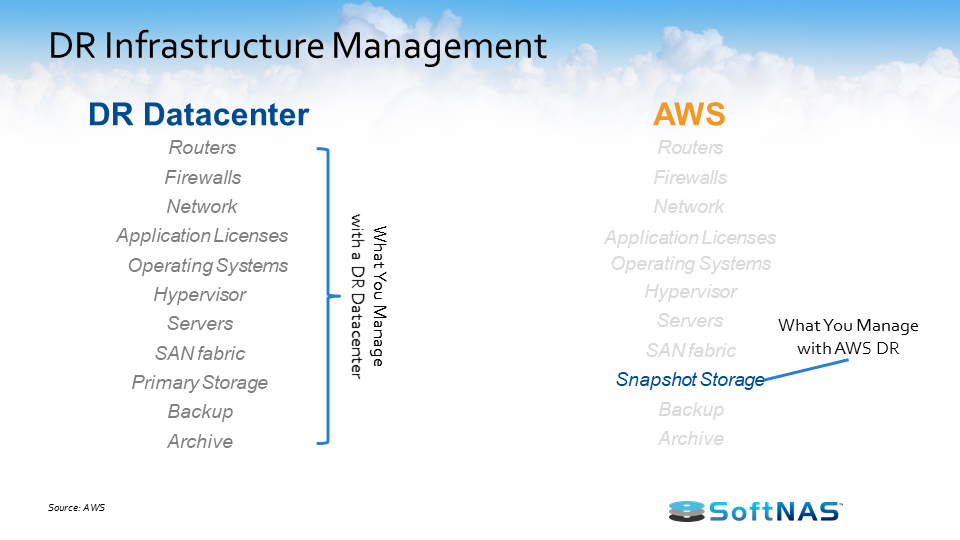
The beauty of using AWS to manage your DR is you’re only responsible for your snapshot storage. AWS is handling routers, firewalls, operating systems, and more. AWS just takes all that off your hands, so you can focus on more important tasks and projects.
How does AWS disaster recovery mirror your DR data center?
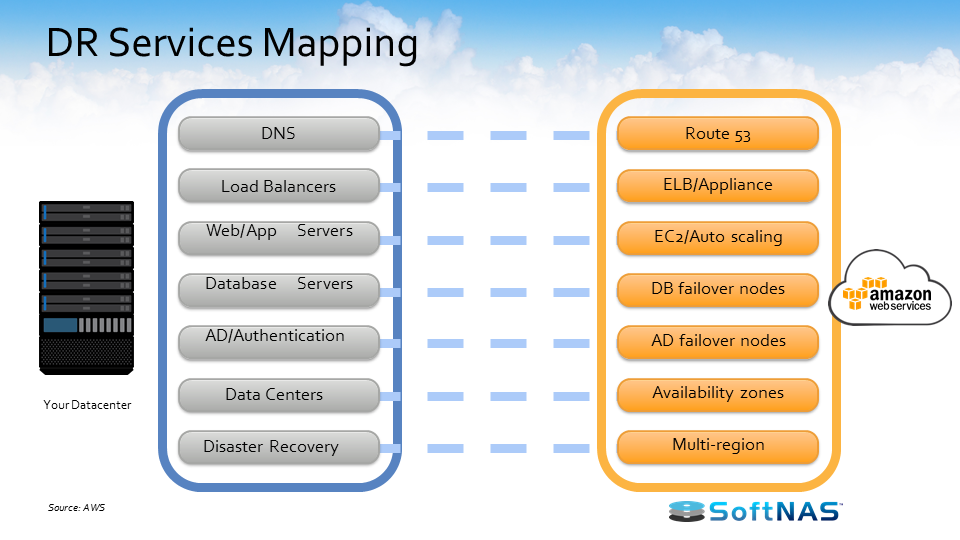
The image above shows traditional DR services and AWS services. For example: with DNS, AWS has Route 53; for load balancers, AWS has Elastic Load Balancing; web servers can be EC2 or auto-scaling. Data centers are managed by availability zones.
Because everything is on AWS, enterprise security standards are met. AWS is always up to date with certification, whether it’s ISO, HIPAA, ITAR, or other compliance standards.
There is also the physical security aspect. AWS datacenters are highly secure, located in nondescript facilities and physical access is strictly controlled. They log all the physical access to their data centers. With hardware and software networking, they have systematic change management. Updates are phased and they do safe storage decommission. There is also automated monitoring, self-audits, and advanced network protection.
AWS Disaster Recovery Architecture
AWS Disaster Recovery Architecture? Disaster recovery is the process by which an organization anticipates and addresses technology-related disasters. IT systems in any company can go down unexpectedly due to unforeseen circumstances, such as power outages, natural events, or security issues.
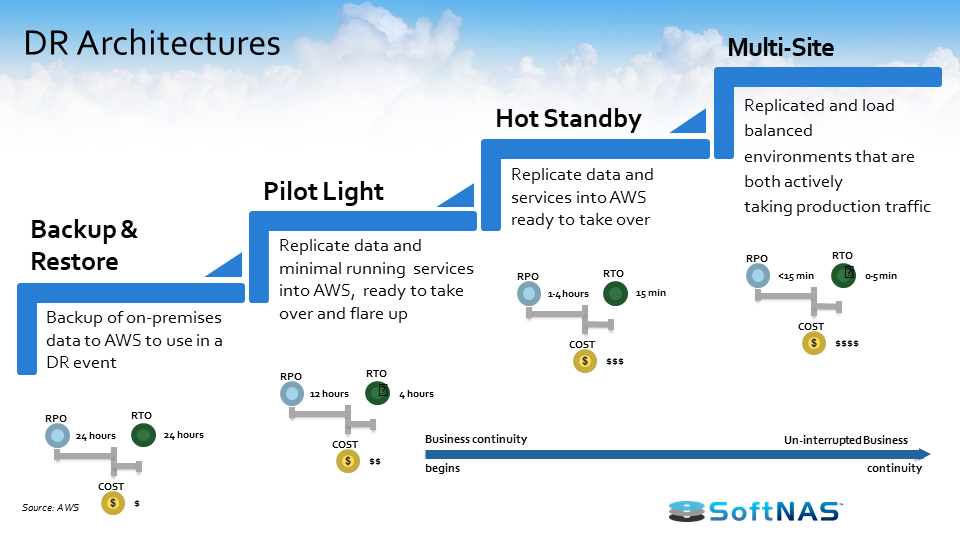
Let’s look at some DR architecture and scenarios for AWS. There is 4 main AWS DR architecture:
- Backup & Restore
- Pilot Light
- Hot Standby
- Multi-site
Before we discuss the architectures, let’s look at some of the AWS services involved with DR. For backup and restore, you’re not using too many AWS core services. You’re going to be using Amazon S3, Glacier, SoftNAS virtual NAS appliance (for replication), Route 53, and VPN.
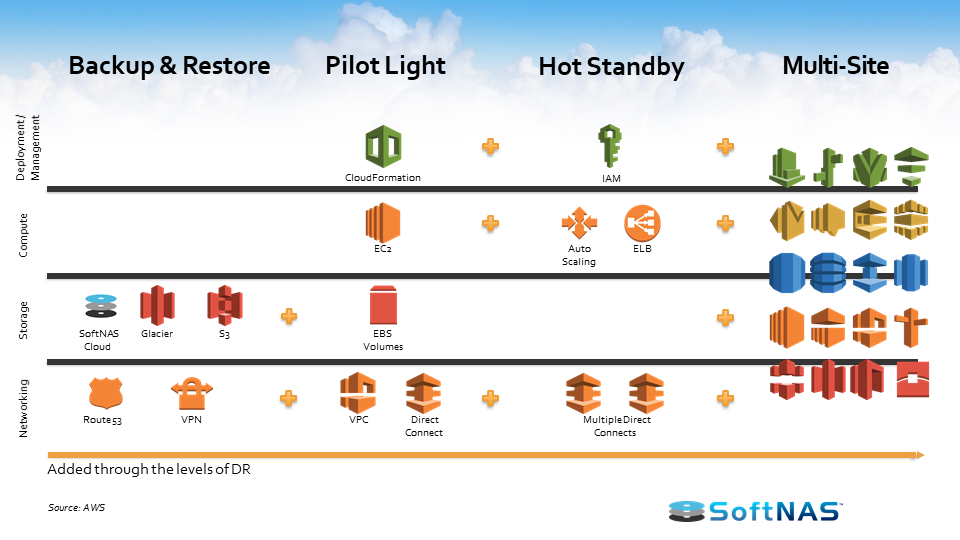
As you move on to Pilot Light, you’re going to add in CloudFormation, EC2, EBS volumes, Amazon VPCs and DirectConnect. For Hot Standby, you add in Auto Scaling, Elastic Load Balancing, and setup also multiple Direct Connects. For Multi-site, there’s a whole host of AWS services to add in.
1) AWS Backup & Restore Architecture
The way to back up and restore work is shown in the image below. We have an on-premises data center on the left and AWS DR infrastructure on the right.
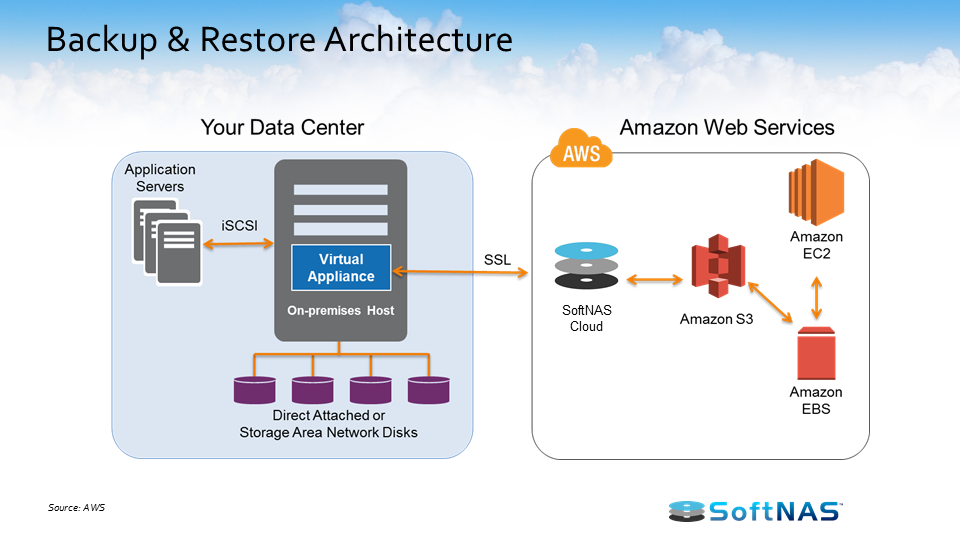
On the left, you have a data center using the iSCSI file protocol, and then you’ve got a virtual NAS on top of that managing file storage. What you can do with AWS DR is use a combination of SoftNAS Cloud NAS, Amazon S3, EC2, and EBS to go in and manage your backup architecture.
In traditional environments, data is backed up to the DR data center. It’s offsite, so if something fails it’s going to take a long time to restore your system because you have to pull them and then pull the backup data from them.
Amazon S3 and Glacier are really good for this. Using a service like SoftNAS Cloud NAS Filer enables you to use snapshots of your on-premises data and copy them into S3 for backup. The benefit of this is you can also arm your snapshot data volumes to give you a highly durable backup.

It’s pretty cost-effective since you’re not paying a lot of money for it. In case of disaster, you’re going to retrieve your backups from S3 and bring up the required infrastructures. So these are the EC2 instances with prepared AMIs, load balancing, etc. You restore the system from a backup.
With the backup and restore architecture, it’s a little bit more time-consuming. It’s not instant, but there is a workaround for that.
With SoftNAS AWS NAS, you can set up replication with SnapReplicate. It makes your data instantly available instead of having to wait for it to download and back it up. It’s now all instantly available to you. So your RTO and your RPO go from hours or days into minutes or just one or two hours.
2) AWS Pilot Light Architecture
Moving on to the Pilot Light architecture, this is a scenario in which a minimal version of your primary data center’s architecture is always running in the cloud.
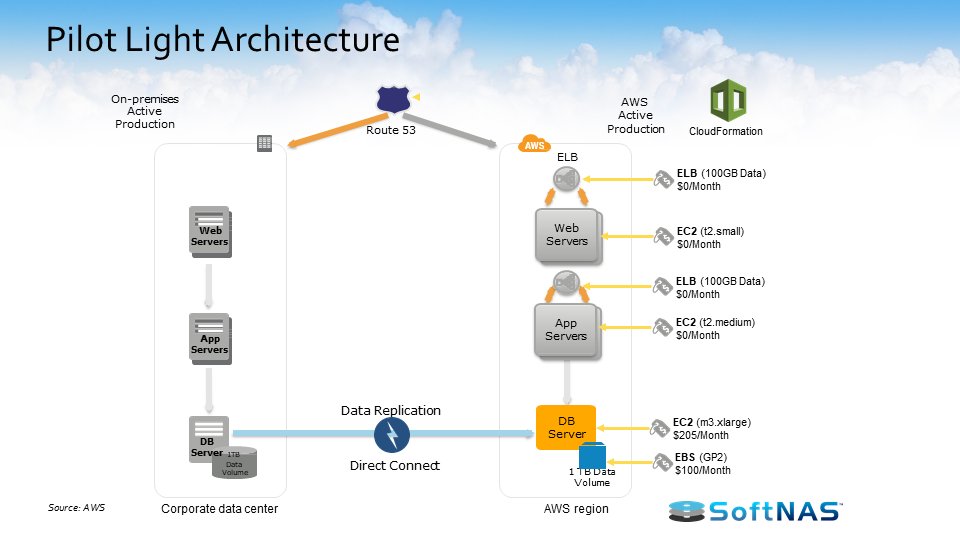
It’s pretty similar to a Backup and Restores scenario. With AWS, you can maintain the power of the pilot light by configuring and running your most critical core elements over your system in AWS. When the time comes for recovery, you can rapidly provision a full-scale production environment around the critical core.
To prepare for the Pilot Light architecture, you replicate all of your critical data to AWS. You prepare all of your required resources for your automatic start. Including the AMI, network settings, and load balancing. We even recommend reserving a few instances too.

In case of disaster, you automatically bring up the resources around the replicated core data set. Then you can scale the system as needed to handle your current production traffic. Again, one of the benefits of AWS is you can scale higher or lower based on your current needs.
3) AWS Hot Standby Architecture
Moving on to the Hot Standby architecture, this is a DR scenario which is a scaled-down version of a fully-functional environment. It’s always running in the cloud. So basically a warm standby kind of extends to Pilot Light elements and it kind of further reduces the recovery because some of your services are always running in AWS – they’re not idle and there’s no downtime with them. By identifying your business-critical systems, you can fully duplicate them on AWS and have them always on.
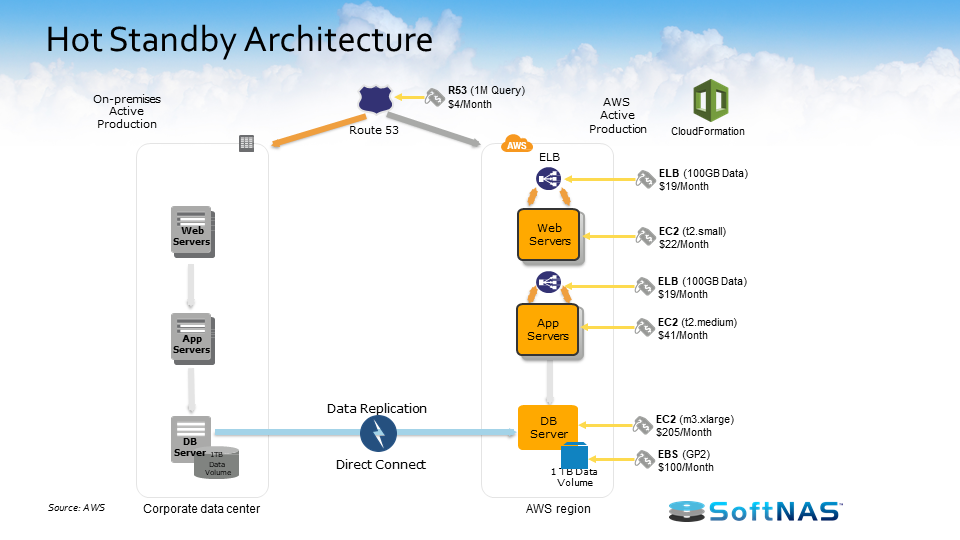
Hot Standby handles production workloads pretty well. To prepare, you again replicate all of your critical data to AWS. You prepare all of your required resources and your reserved instances. In case of disaster, you automatically bring up the resource around the replicated core dataset. You scale the system as needed to handle your current production traffic.

The objective of the Hot Standby is to get you up and running almost instantly. Your RTO can be about 15 minutes and your RPO can vary from one 1 to 4 hours.
4) AWS Multi-site Architecture
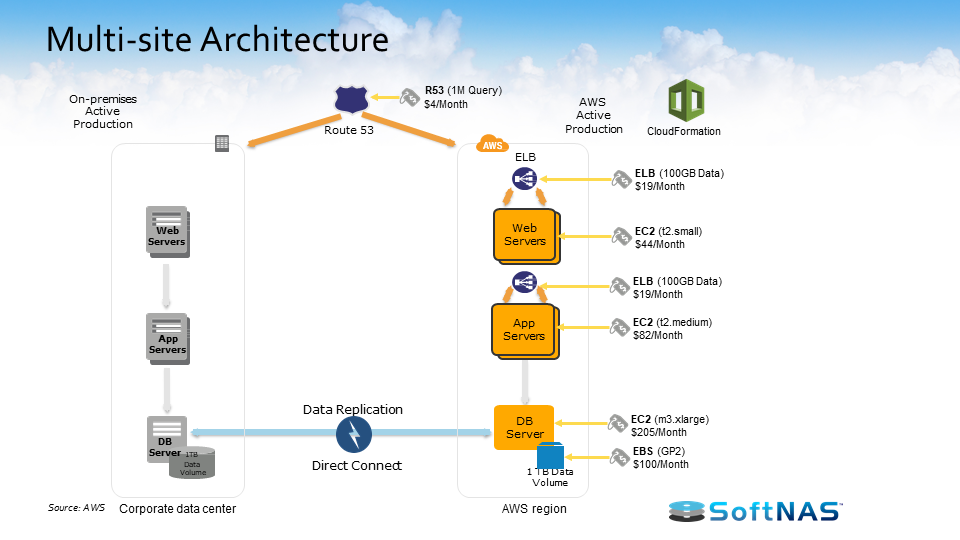
Finally, we have the Multi-site architecture. This is where your AWS DR infrastructure is running alongside your existing on-site structure. Instead of it being active-inactive, it’s going to be an active-active configuration. This is the most instantaneous architecture for your DR needs. At any moment, once your on-premises data center goes down, AWS will go ahead and pick up the workload almost immediately.

You’ll be running your full production load without any kind of decrease in performance so it immediately fills over all your production load. All you have to do is kind of just adjust your DNS records to point to AWS. Your RTO and your RPO are within minutes so no need to worry about spending time re-architecting everything.
AWS Disaster Recovery Example

Here’s an example showing how our customers are using disaster recovery on AWS. The customer is using AWS to kind of manage their business applications and they’ve broken them down into Tier 1, Tier 2, and Tier 3 apps.
For Tier 1 apps that need to be up and running 24/7, they’ve got their EC2 instances for all services running at all times. Their in-house and their AWS infrastructure are load balanced and configured for auto-failover. They do the initial data synchronization using in-house backup software or FTP. Finally, they set up replication with SoftNAS Cloud NAS to automatically failover in minutes.
With Tier 2 apps, they’re configuring only the critical core elements of the system – they don’t configure everything. Again, they’ve got their EC2 instances running only for the critical services. They pre-configured their AMIs for the Tier 2 apps that can be quickly provisioned. Their cloud infrastructure is load balanced and configured for AMI failover. They did the initial data sync with their backup software. Finally, replication was set up with SoftNAS Cloud NAS.
For Tier 3 apps, where the RPO and RTO aren’t too strict, they replicated all their data into S3 using SoftNAS Cloud NAS. Again, they did a sync with their backup software. They went ahead and pre-configured their AMIs. And then also their EC2 incidents are spun up from objects within S3 to a manual process, but they’re able to get there pretty tier pretty quickly.
To start using AWS Disaster Recovery, check out the resources below:
Try SoftNAS AWS NAS Storage to start managing DR in the cloud: